LaTeX Lint
Abstract
LaTeX Lint is a linter to detect common LaTeX and academic writing issues.
VS Code Extension Version is available.
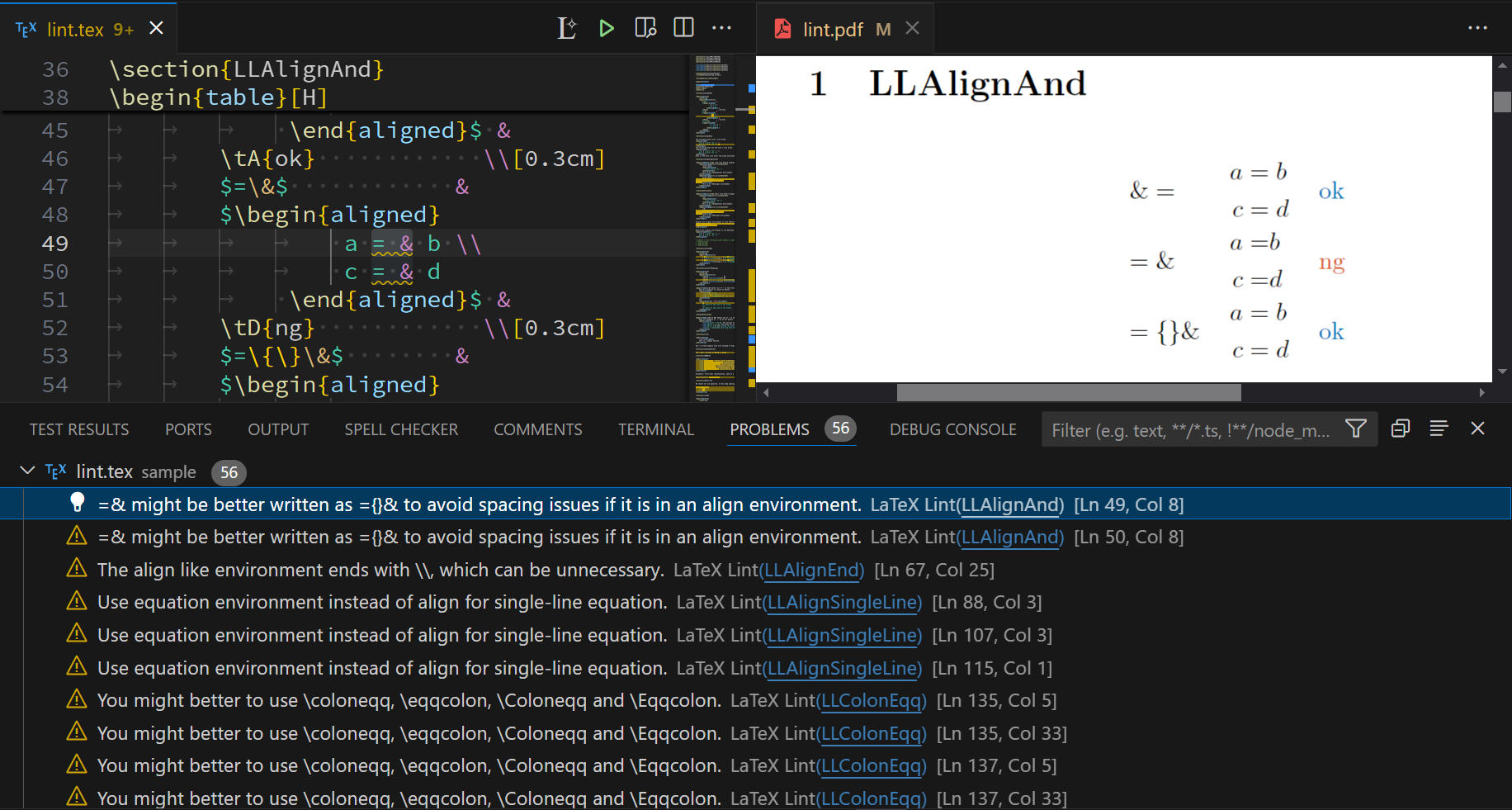
Web Version is also available.
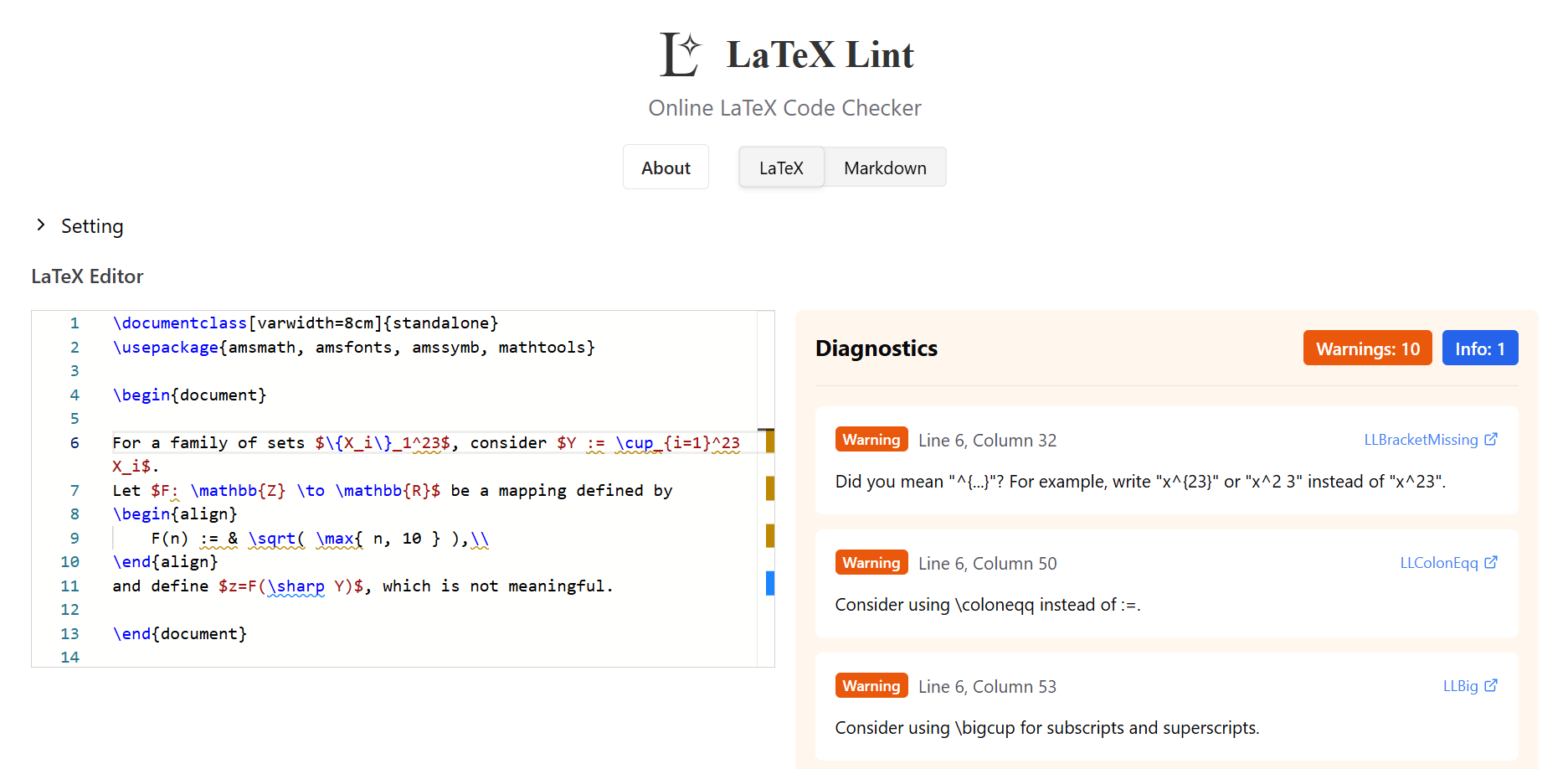
Rules
The detected rules are listed below.
We strongly recommend enabling only the rules that match your preferences and writing style.
See LaTeX Lint: Choose Detection Rules for details.
- LLAlignAnd (detect
=&, \leq&, \geq&, etc.)
- LLAlignEnd (detect
align environment ends with \\)
- LLAlignSingleLine (detect
align environment without \\)
- LLArticle (detect wrong article usage)
- LLBig (detect
\cap_, \cup_, etc.)
- LLBracketCurly (detect
\max{ and \min{)
- LLBracketMissing (detect
^23, _23, disabled by default)
- LLBracketRound (detect
\sqrt(, ^(, and _()
- LLColonEqq (detect
:=, =:,::=, and =::)
- LLColonForMapping (detect
: for mapping)
- LLCref (detect
\ref, disabled by default)
- LLDots (detect
...)
- LLDoubleQuotes (detect
")
- LLENDash (detect the dubious use of
-(hyphen))
- LLEqnarray (detect
eqnarray environment)
- LLErrCompOps (detect incorrect comparison operator orders)
- LLFootnote (detect space before
\footnote)
- LLHeading (detect heading level jumps)
- LLLlGg (detect
<< and >>)
- LLMathPunctuation (detect incorrect punctuation in math environments)
- LLNonASCII (detect fullwidth ASCII characters)
- LLNonstandard (detect nonstandard mathematical notations)
- LLOperator (detect operators with incorrect spacing)
- LLPeriod (detect abbreviation periods in LaTeX)
- LLRefEq (detect
(\ref{eq:)
- LLSharp (detect
\sharp likely to be a misuse of \#)
- LLSI (detect
KB, MB, GB, etc. without \SI)
- LLSortedCites (detect unsorted cites)
- LLSpaceEnglish (detect the lack of space for English)
- LLSpaceJapanese (detect the lack of space for Japanese, disabled by default)
- LLT (detect
^T, disabled by default)
- LLTextLint (part of textlint features)
- LLThousands (detect
1,000 etc.)
- LLTitle (detect dubious title case in
\title{}, \section{}, etc.)
- LLUnRef (detect unreferenced figure and table labels)
- LLURL (detect unnecessary info in URLs)
- LLUserDefined (detect Regexes in
latexlint.userDefinedRules)
Please also refer to sample/lint.pdf and our Japanese article (日本語解説記事) if needed.
LLAlignAnd
Detect =& of align environments in .tex and .md files.
Use &= or ={}& to avoid extra spaces.
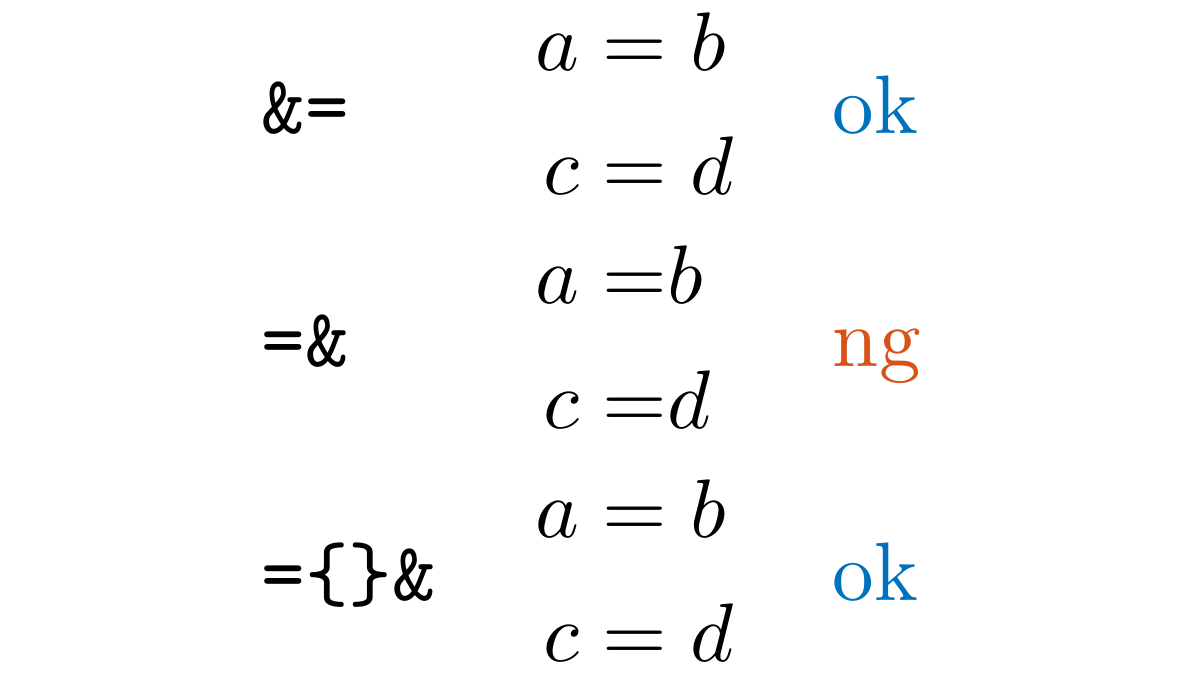
We also detect \neq&, \leq&, \geq&, etc.
References:
Relation spacing error using =& in aligned equations (Stack Exchange)
LLAlignEnd
Detect align, gather, and other environments end with \\ in .tex and .md files.
This \\ would be unnecessary.
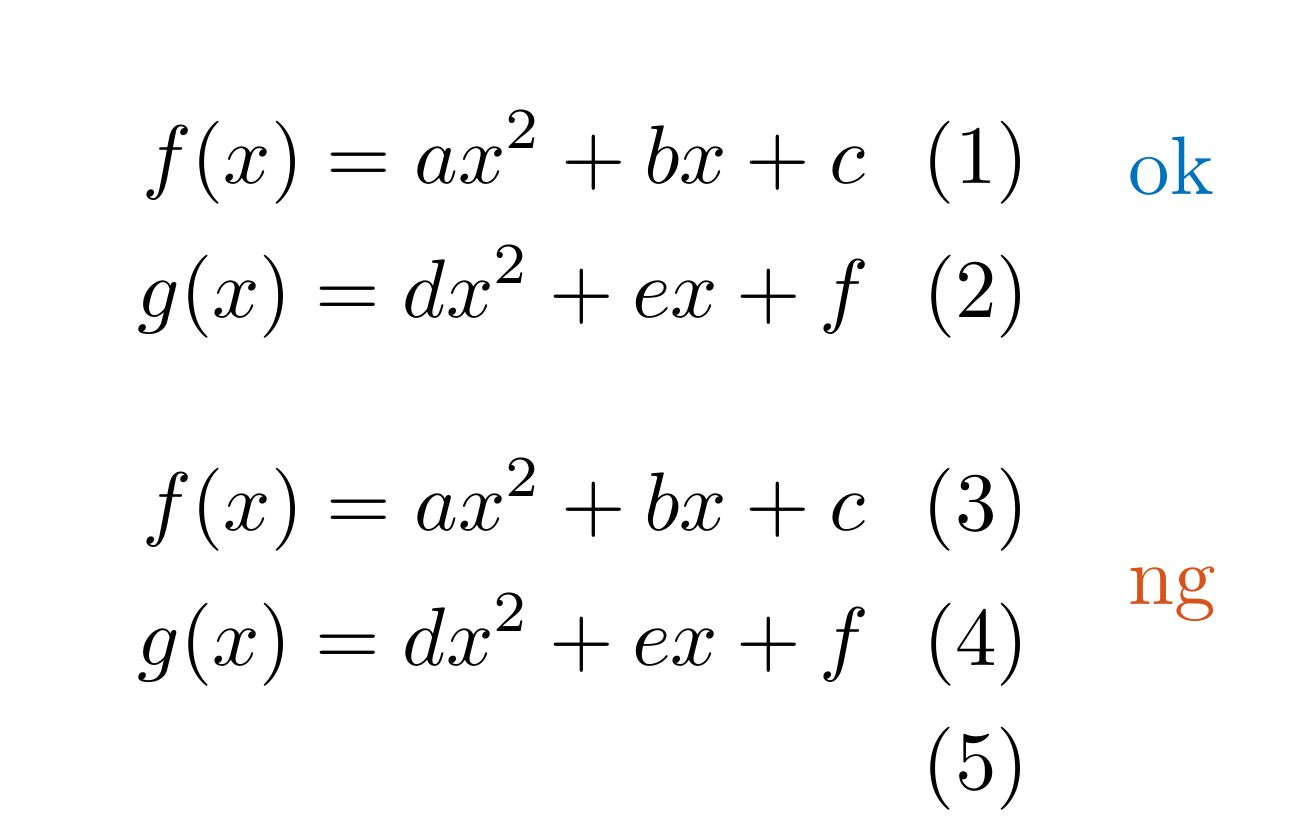
LLAlignSingleLine
Detect align environment without \\ in .tex and .md files.
Single-line equations are recommended to use the equation environment.

The spacing of the align environment is different from the equation environment with only one equation. Official documentation of amsmath package assumes the use of the equation environment for a single equation.
To rewrite \begin{align} ... \end{align} to \begin{equation} ... \end{equation}, you can rename the command by LaTeX Lint: Rename Command or Label.
References:
What is the difference between align and equation environment when I only want to display one line of equation? (Stack Exchange)
LLArticle
Detect wrong article usage in .tex and .md files.

Examples are as follows:
Single letters:
- NG:
a $a$ → OK: an $a$
- NG:
a $n$ → OK: an $n$
- NG:
a $x$ → OK: an $x$
- NG:
an $u$ → OK: a $u$
Abbreviations:
- NG:
a EM → OK: an EM (Expectation–Maximization)
- NG:
a EVD → OK: an EVD (Eigenvalue Decomposition)
- NG:
a FFT → OK: an FFT (Fast Fourier Transform)
- NG:
a NP-hard → OK: an NP-hard (Non-deterministic Polynomial-time hard)
- NG:
a LSTM → OK: an LSTM (Long Short-Term Memory)
- NG:
a LTI → OK: an LTI (Linear Time-Invariant)
- NG:
a MLE → OK: an MLE (Maximum Likelihood Estimation)
- NG:
a MSE → OK: an MSE (Mean Squared Error)
- NG:
a ODE → OK: an ODE (Ordinary Differential Equation)
- NG:
a RNN → OK: an RNN (Recurrent Neural Network)
- NG:
a RKHS → OK: an RKHS (Reproducing Kernel Hilbert Space)
- NG:
a SDE → OK: an SDE (Stochastic Differential Equation)
- NG:
a SVD → OK: an SVD (Singular Value Decomposition)
- NG:
a SVM → OK: an SVM (Support Vector Machine)
- NG:
a XOR → OK: an XOR (Exclusive OR)
LaTeX commands:
- NG:
a $\mathbb{R}$-valued → OK: an $\mathbb{R}$-valued
- NG:
a $L^1$ → OK: an $L^1$
- NG:
a $\ell^2$ → OK: an $\ell^2$
- NG:
a $\mathcal{L}^\infty$ → OK: an $\mathcal{L}^\infty$
References:
Should individual letters be preceded with "an"? (Stack Exchange)
LLBig
Detect \cap_, \cup_, \odot_, \oplus_, \otimes_, \sqcup_, \uplus_, \vee_, and \wedge_ in .tex and .md files.
You should likely use \bigcap, \bigcup, \bigodot, \bigoplus, \bigotimes, \bigsqcup, \biguplus, \bigvee, and \bigwedge instead.
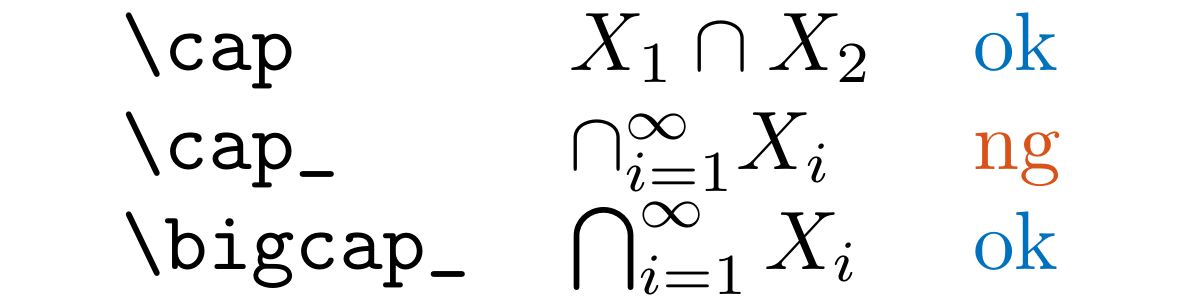
References:
Formatting the union of sets (Stack Exchange)
LLBracketCurly
Detect \max{ and \min{ in .tex and .md files.
You should likely use \max( and \min( instead, or add a space like \max { or \min { to make it clear.
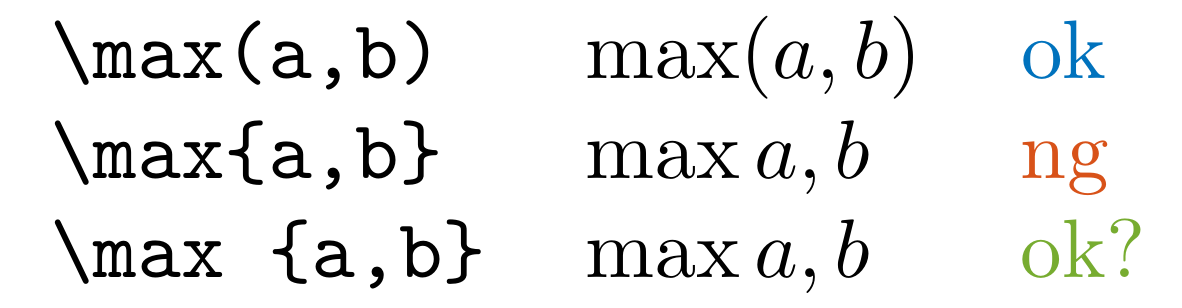
LLBracketMissing
Detect cases such as ^23, _23, ^ab, and _ab in .tex files. Clarify the scope of the superscript and subscript by adding {} or a space.
This rule is disabled by default.
Filenames / URLs / labels are ignored, such as in \includegraphics{figure_23} or \url{http://example.com/abc_123}.
This rule is disabled in the preamble (only if \begin{document} exists, before that).
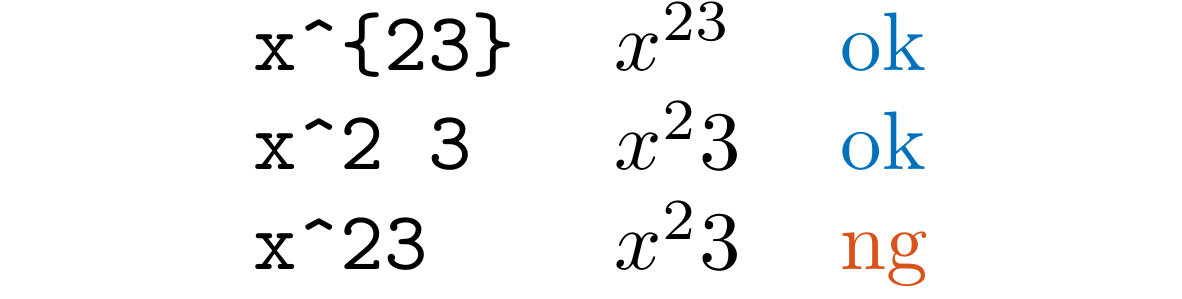
LLBracketRound
Detect \sqrt(, ^(, and _( in .tex and .md files.
You should likely use \sqrt{, ^{, and _{ instead.
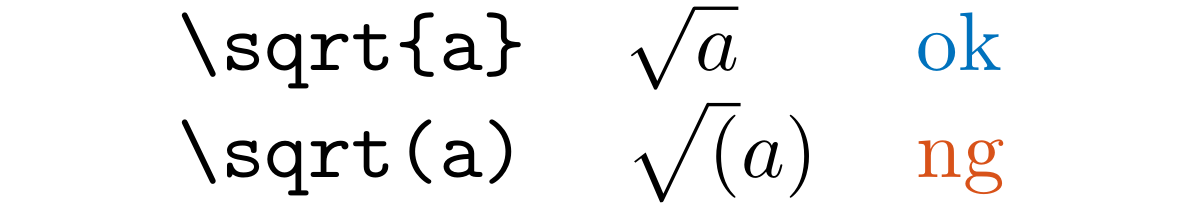
LLColonEqq
Detect :=, =:, ::=, and =:: in .tex and .md files.
You should likely use \coloneqq, \eqqcolon, \Coloneqq, and \Eqqcolon in the mathtools package instead.

The colon is slightly too low in :=, but vertically centered in \coloneqq.
References:
How to typeset $:=$ correctly? (Stack Exchange)
What is the latex code for the symbol "two colons and equals sign"? (Stack Exchange)
Detect : which seems to be used for mapping in .tex and .md files.
You likely want to use \colon instead.
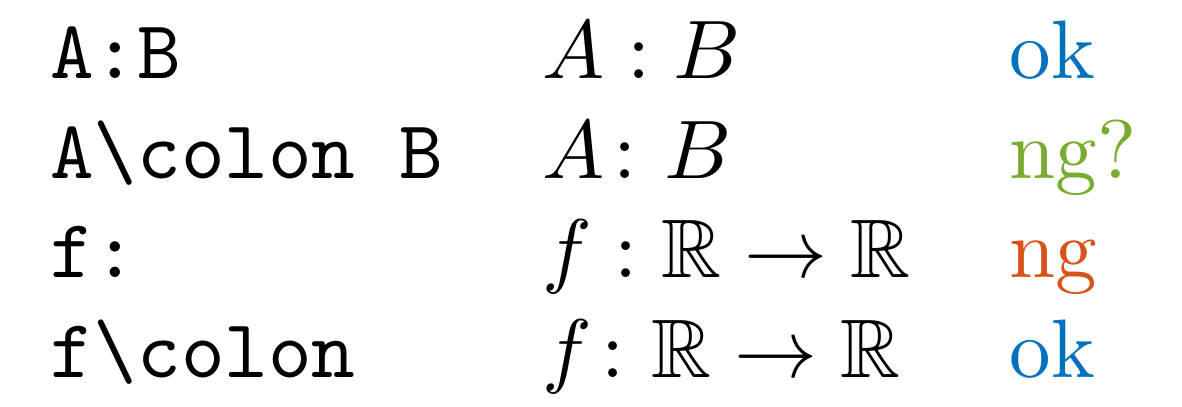
\colon is recommended for the mapping symbol. : is used for ratios, such as 1:2.
When \to, \mapsto, or \rightarrow appear, the rule looks back up to 10 words to find the nearest :, using some heuristics to suppress false positives.
References:
Using \colon or : in formulas? (Stack Exchange)
LLCref
Detect \ref in .tex files.
You should likely use \cref or \Cref in the cleveref package instead.
This rule is disabled by default.
We prefer this package because it can automatically add prefixes like "Sec." or "Fig.". We can keep the consistency of the reference format.
This rule is disabled in the preamble (only if \begin{document} exists, before that).
LLDots
Detect ... in .tex files.
Since \dots automatically selects the appropriate dots and adjusts the spacing, it is recommended to use \dots instead of ....
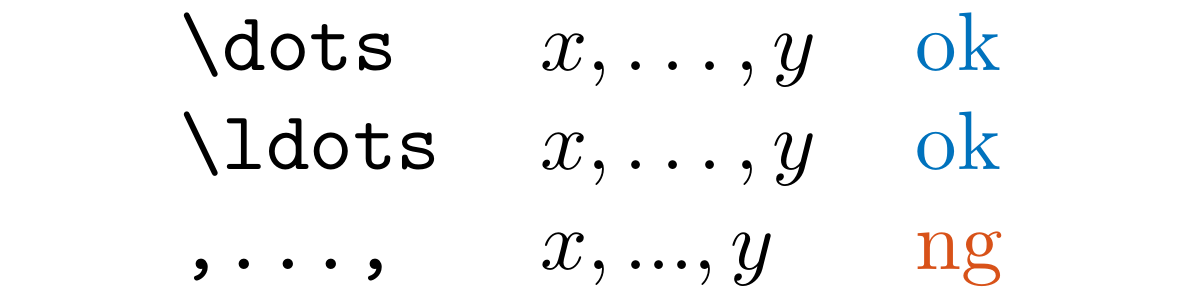
We also detect +...+ (... surrounded by operators) and 0.333... (... following a number).
(Admittedly, there is probably no very objective evidence that \dots is superior to ..., so it may be a matter of style preference. However, as the references suggest, \dots is recommended by many people.)
References:
some common (la)tex errors
Is there a difference between \ldots and \textellipsis? (Stack Exchange)
16.2.6 Dots, horizontal or vertical
LLDoubleQuotes
Detect " in .tex files. Use ``XXX'' instead for double quotation.
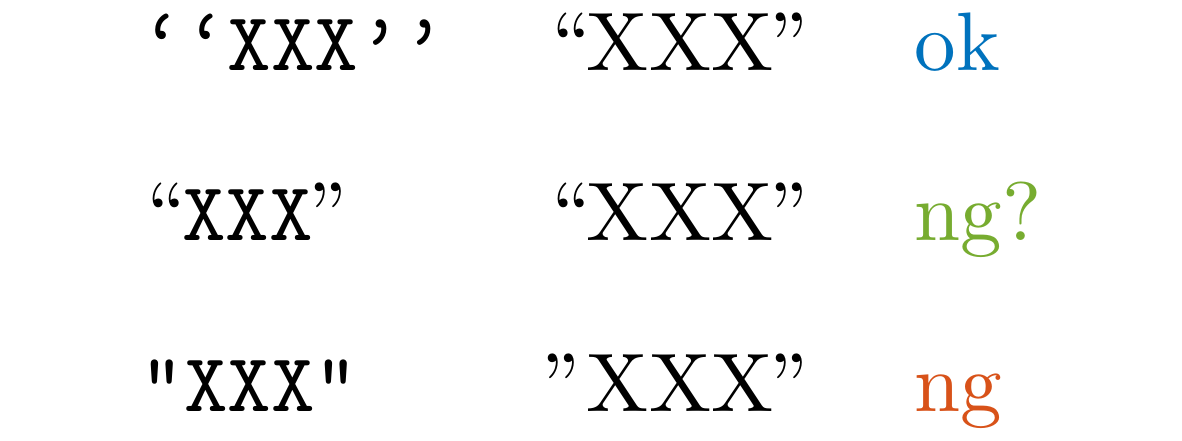
As for “XXX”, there is no problem in most cases and thus we don't detect it, but we prefer to use ``XXX'' for consistency.
You can also use \enquote{XXX} with the csquotes package.
References:
What is the best way to use quotation mark glyphs? (Stack Exchange)
LLENDash
Detect the dubious use of hyphens in .tex and .md files.
You should likely use -- for en-dash and --- for em-dash.
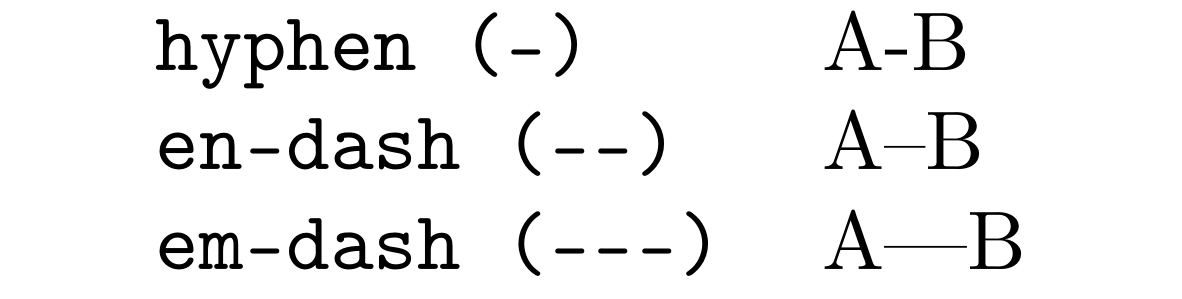
Although this rule is not inherent orthographic "correctness", in a lot of cases, the use of an en dash is preferred.
For example, we detect the following.
Erdos-Renyi (random graph, Erd\H{o}s--R\'enyi)Einstein-Podolsky-Rosen (quantum physics, Einstein--Podolsky--Rosen)Fruchterman-Reingold (graph drawing, Fruchterman--Reingold)Gauss-Legendre (numerical integration, Gauss--Legendre)Gibbs-Helmholtz (thermodynamics, Gibbs--Helmholtz)Karush-Kuhn-Tucker (optimization, Karush--Kuhn--Tucker)
However, we do not detect the following as an exception.
- Common word pairs such as
Real-Valued / Two-Dimensional are skipped when both words are recognized general vocabulary.
Fritz-John (optimization, name of a person)- (We might add more exceptions later.)
We also should use -- instead of - to indicate a range of pages, e.g., 123--456 instead of 123-456. A lot of BibTeX files follow this rule. We do not detect this because it might be just a subtraction.
LLEqnarray
Detect eqnarray environment in .tex and .md files.
You should likely use the align environment instead.
It is known that the eqnarray environment is not recommended because it has some spacing issues.
References:
Why not use eqnarray? (TeX FAQ)
LLErrCompOps
Detect suspected typographical errors in the sequence of comparison operators in .tex and .md files.
The target of detection includes <=, \le =, \leq =, etc.
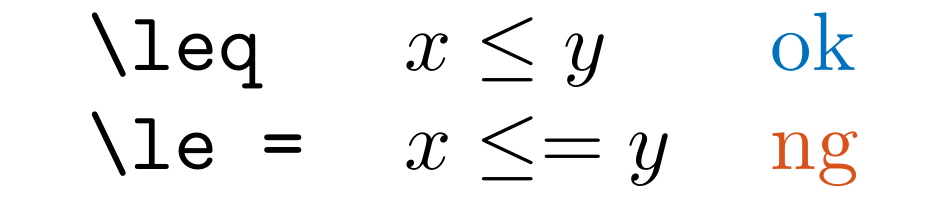
In markdown files, <= and => are ignored.
Detect unnecessary space before \footnote command in .tex files.
You should likely remove the space before \footnote, or add a percentage sign % at the end of the previous line to avoid unwanted space in the output.

Whether putting footnote markers before or after punctuation marks is a style choice, and thus we do not enforce a specific style.
References:
Where do I place a note number in relation to punctuation? (MLA Style Center):
Whenever possible, a note number should be placed at the end of a sentence.
Young wizards at Hogwarts learn how to throw flames by incanting “incendio.”2
If clarity requires that a note be placed somewhere other than at the end of a sentence, the note should generally be placed after a punctuation mark.
Despite Fredric Jameson’s influential imperative to historicize,5 Chakrabarty has criticized the “continuous, homogenous” characteristics of this understanding of history (111).
An exception is the dash, which follows a note number.
Positioned in the margins of each scene, the servant4—immobilized, silent, cast in shadow—uncannily substantiates Rodriguez’s claim.
In general, a note number should follow a closing parenthesis.
Woolf’s first novel, The Voyage Out, was published in 1915. (The original title of the novel was Melymbrosia.)8
Occasionally, however, placing a note number inside a closing parenthesis may help clarify the referent. In the following sentence, for instance, the author intends to elaborate on the meaning of the German word Binnenerzählung in a note.
According to Gail Finney, the frame narrative (as distinct from the embedded narrative, or Binnenerzählung3) prevents “penetration of, and subjective identification with, the protagonist” (322).
Best practice for source editing of footnotes (Stack Exchange):
You can use the semantic-markup package, which provides a Footnote environment. You have to "escape" the end-of-line character by putting a % at the end of the line before the footnote. (Slightly modified by Hiroki Hamaguchi)
Placing footnote mark before or after punctuation?:
The Chicago Manual of Style (CMS) uses footnotes for citations. The footnote mark is placed before the punctuation and links to a reference1. On the other hand, the Modern Language Association (MLA) only uses footnotes for directing the reader to other pertinent information, not for citations,2 and they instruct authors to place the mark after any commas or full-stops (but before — dashes).Some people recommend a "logical" style. Place the footnote mark after the punctuation if the note is pertinent to the whole sentence, and before if it is only relevant to part of it. (Slightly modified by Hiroki Hamaguchi)
LLHeading
Detect improper heading hierarchy in .tex files.
This rule warns when there are jumps in heading levels, such as going directly from \section to \subsubsection without an intermediate \subsection.
The rule checks the following heading levels:
\chapter\section\subsection\subsubsection
LLLlGg
Detect << and >> in .tex and .md files.
You should likely use \ll and \gg instead.
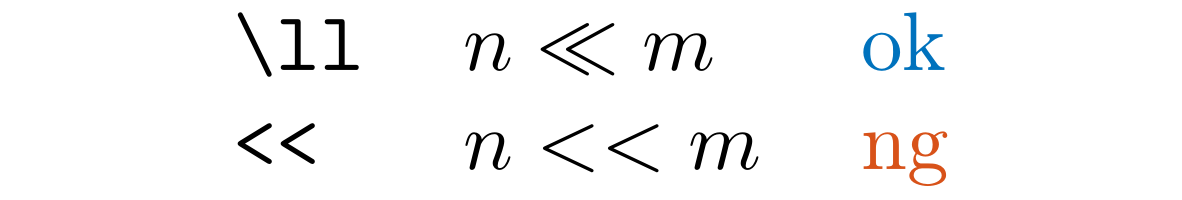
We do not detect << like this one.
I like human $<<<$ cat $<<<<<<<$ dog.
LLMathPunctuation
Detect incorrect punctuation at the end of display math environments in .tex and .md files.
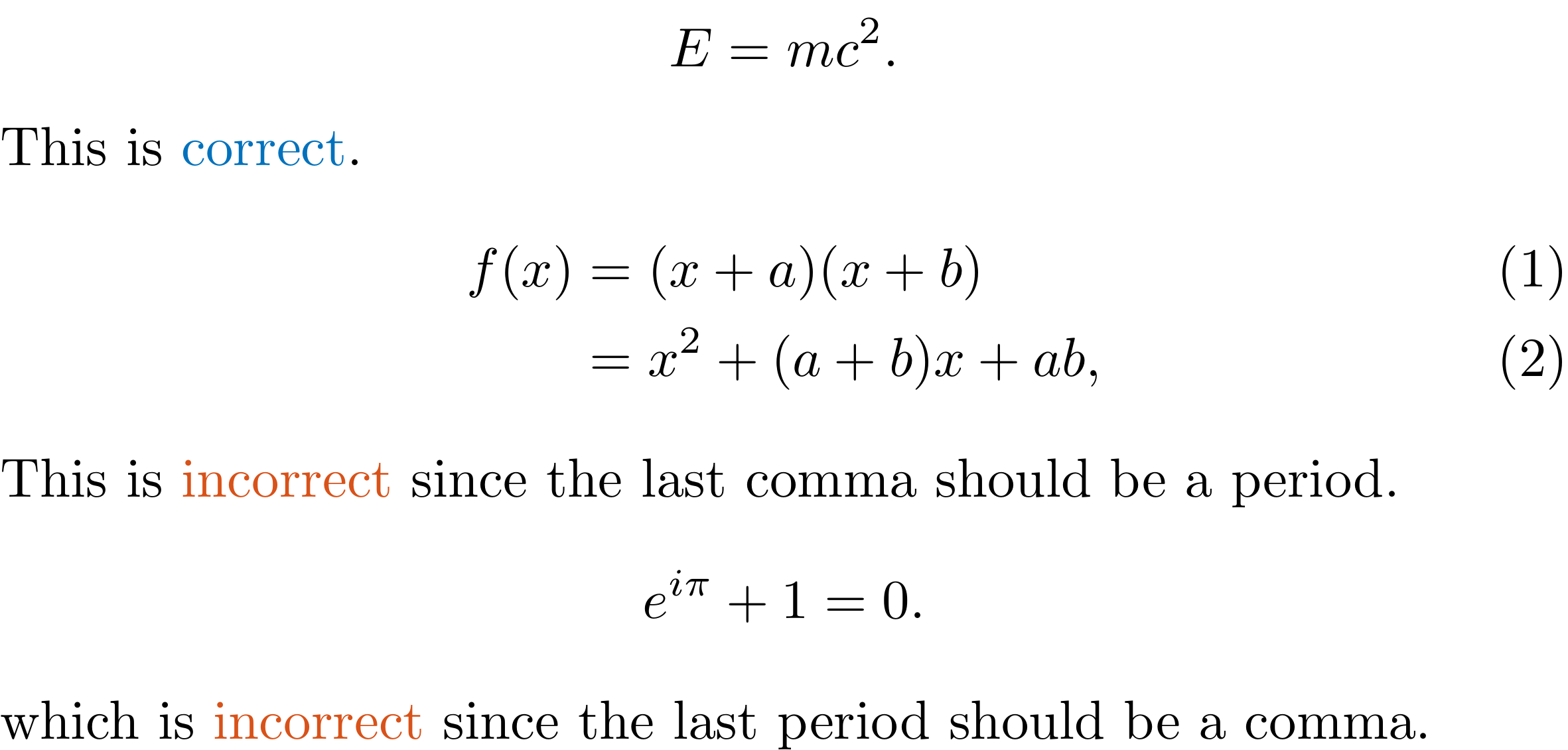
This rule is intended to be further refined in the future.
LLNonASCII
Detect all fullwidth ASCII characters in .tex and .md files.
We detect the following characters.
!"#$%&'*+-/0123456789:;
<=>?@ABCDEFGHIJKLMNOPQRS
TUVWXYZ[\]^_`abcdefghijk
lmnopqrstuvwxyz{|}~
We use the following Regex.
[\u3000\uFF01-\uFF07\uFF0A-\uFF0B\uFF0D\uFF0F-\uFF5E]
Range U+FF01–FF5E reproduces the characters of ASCII 21 to 7E as fullwidth forms. U+FF00 does not correspond to a fullwidth ASCII 20 (space character), since that role is already fulfilled by U+3000 "ideographic space".
Wikipedia
Plus, U+3000 is used for a fullwidth space.
We do not detect the following characters because they are often used in Japanese documents.
- U+FF08
(
- U+FF09
)
- U+FF0C
,
- U+FF0E
.
LLNonstandard
Detect nonstandard mathematical notations in .tex and .md files that are not commonly used in formal academic writing.
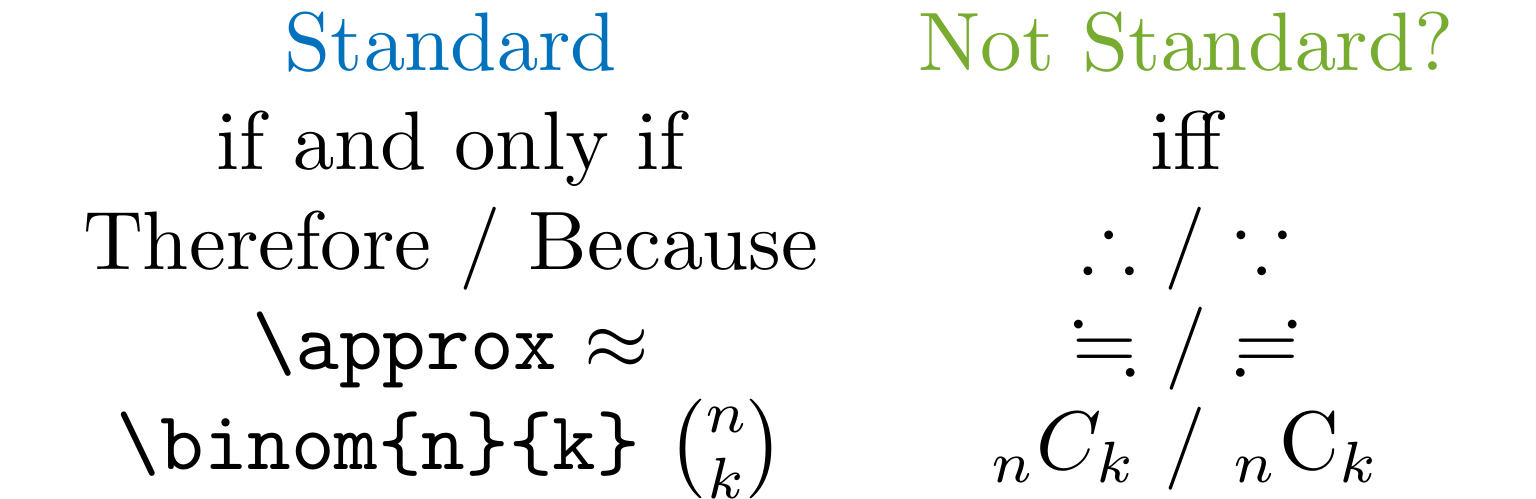
This rule detects the following notations:
The word "iff"
While commonly used in informal mathematical writing, "iff" (if and only if) is preferred to be written out fully in formal academic writing.
\therefore and \because commands
These symbols are not generally used in formal writing.
\fallingdotseq and \risingdotseq commands
These are nonstandard notation symbols. \approx is preferred in formal writing.
{}_n C_k notation for combinations
The notation {}_n C_k for combinations is often used in Japan, but not standard in international academic writing. We recommend the standard binomial notation \binom{n}{k} instead.
This rule only detects exact matches to avoid false positives.
References:
Therefore sign (Wikipedia):
While it is not generally used in formal writing, it is used in mathematics and shorthand.
数学英語 (河東泰之, Japanese article):
The symbols ∀ and ∃ are considered shorthand notations for writing on blackboards, etc., and are not used in papers unless in mathematical logic. In fact, there are some examples of ∀ being used in my papers, but that is because I couldn't fully correct what my co-authors wrote. Similarly, the abbreviation "iff" for "if and only if" is also considered a shorthand notation and is inappropriate for use in papers.
The symbol ∵ is included in the JIS code and is named \because in TeX, but as far as I know, it is rarely used in Western countries. (The symbol ∴ is used more than this.) I've seen Japanese people write this on blackboards and ask "What does that mean?" many times. Another mathematical symbol that is not used in Western countries is ≒. The symbol commonly used to represent "approximately equal" is ≈. (Translated by Hiroki Hamaguchi)
組合せ (数学) (Japanese Wikipedia):
Pierre Hérigone defined the ${}_n C_k$ notation in his 1634 work "Practical Arithmetic". However, this number appears frequently in all areas of mathematics and is usually written as $\binom{n}{k}$. (Translated by Hiroki Hamaguchi)
LLOperator
Detect operators in the form of \mathrm{...} that have incorrect spacing in .tex and .md files.

For example, to typeset the rank function, we can load the amsmath package and use \operatorname{rank} A, or use \rank A with \DeclareMathOperator{\rank}{rank} in the preamble.
To avoid false positives, we only detect specific cases. There may be many false negatives. Even if LaTeX Lint does not detect an issue, we highly recommend using the alternatives mentioned above for better spacing, readability, and to avoid potential issues.
References:
What's the difference between \mathrm and \operatorname? (Stack Exchange)
LLPeriod
Detect abbreviation periods in .tex files.
This rule checks e.g., i.e., a.k.a., i.i.d., w.r.t., w.l.o.g., and resp. when followed by a space.
LaTeX considers the period in these abbreviations as the end of a sentence, which can lead to extra spacing.
You should use \ (e.g., e.g.\ ) to avoid spacing issues, or add a comma (e.g., e.g.,).
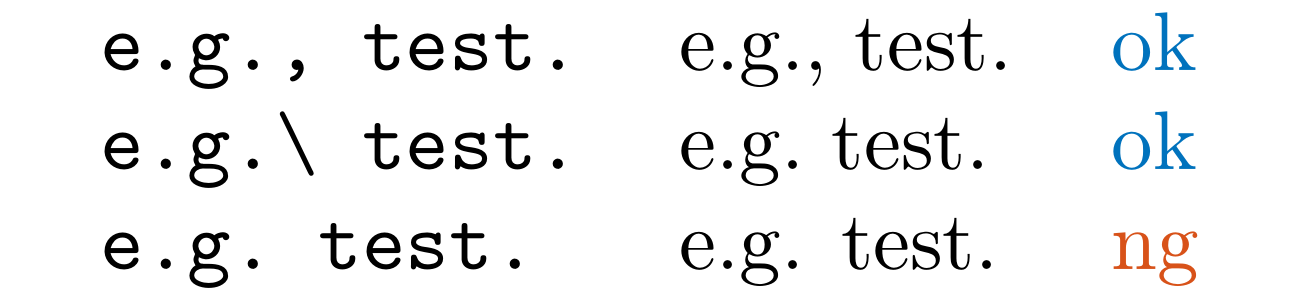
References:
Is a period after an abbreviation the same as an end of sentence period? (Stack Exchange)
LLRefEq
Detect (\ref{eq: in .tex files.
You should likely use \eqref{eq: instead. This command automatically adds parentheses around the reference.
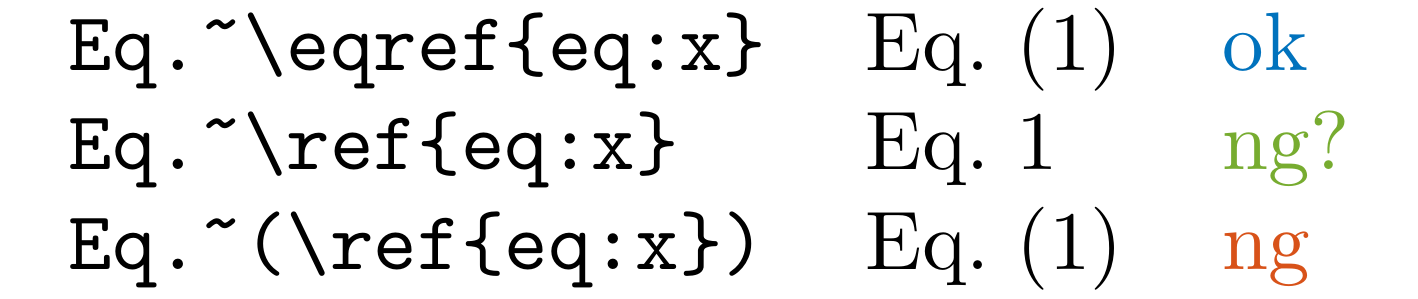
What we want to detect are typos like the following:
From Fig.~\ref{fig:sample} and Eq.~\ref{eq:sample}, we can see that...
From Fig. 1 and Eq. 1, we can see that...
In many cases, equation numbers are expected to be referenced in a parenthesized format like (1). This is the standard style and is commonly used in the amsmath package and many papers and books.
From Fig.~\ref{fig:sample} and Eq.~(\ref{eq:sample}), we can see that...
From Fig.~\ref{fig:sample} and Eq.~\eqref{eq:sample}, we can see that...
From \cref{fig:sample} and \cref{eq:sample}, we can see that...
From Fig. 1 and Eq. (1), we can see that...
However, not all \ref{eq: are necessarily wrong, and there may be intentional uses. Therefore, it is not desirable to mechanically detect such cases.
As a preventive measure, we aim to detect (\ref{eq: and encourage the use of \eqref{eq:. Then, you can manually check the cases \ref{eq: that are not detected and decide whether they are intentional or not.
Although it may not be perfect, this approach can help reduce the likelihood of overlooking such typos.
LLSharp
Detect \sharp in .tex and .md files.
You should likely use \# instead for the number sign.
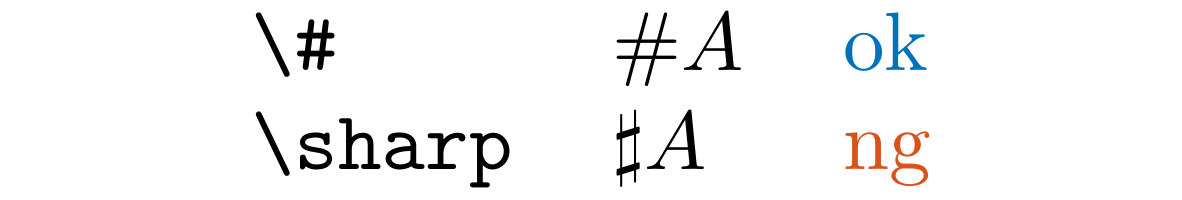
\sharp is used for the musical symbol. We only report it when some heuristic conditions are met.
LLSI
Detect KB, MB, GB, TB, PB, EB, ZB, YB, KiB, MiB, GiB, TiB, PiB, EiB, ZiB, and YiB without \SI in .tex files.
You should likely use \SI instead, like \SI{1}{\kilo\byte}(10^3 byte) and \SI{1}{\kibi\byte}(2^{10} byte) in the siunitx package.
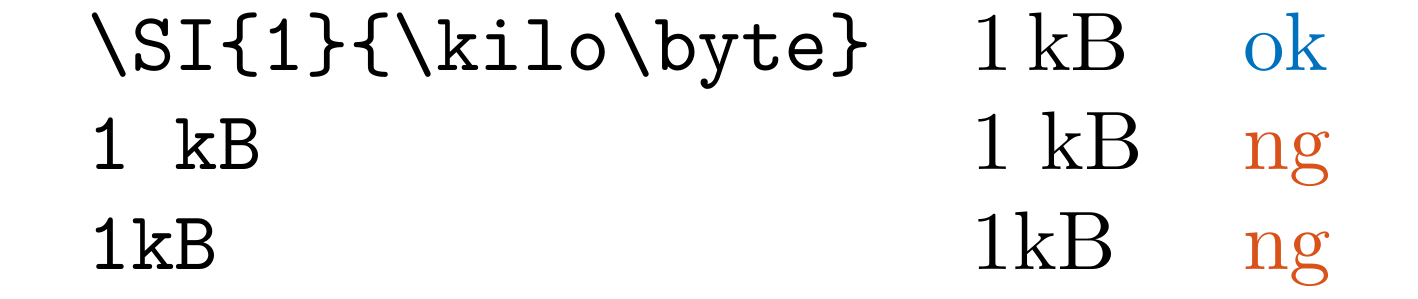
| Prefix |
Command |
Symbol |
Power |
| kilo |
\kilo |
k |
3 |
| mega |
\mega |
M |
6 |
| giga |
\giga |
G |
9 |
| tera |
\tera |
T |
12 |
| peta |
\peta |
P |
15 |
| exa |
\exa |
E |
18 |
| zetta |
\zetta |
Z |
21 |
| yotta |
\yotta |
Y |
24 |
It would be better to use \SI for units such as m, s, kg, A, K, mol, and rad.
LLSortedCites
Detect unsorted multiple citations in .tex files.
Multiple citations like \cite{b,a} can be displayed as [2,1] instead of the sorted order [1,2]. Note that this is unrelated to whether you are using a style that numbers in order of appearance, like unsrt.
(Actually, when I submitted my thesis to a journal, I got a reviewer comment about this. This issue is especially noticeable with styles like plain.)
This rule heuristically detects such cases. In general, this can be resolved by using \usepackage{cite} or \usepackage[sort&compress]{natbib}.

Since this rule performs heuristic-based detection, it may produce false positives.
References:
Numbered ordering of multiple citations (Stack Exchange)
Biblatex, numeric style, multicite: Order of references (Stack Exchange)
LLSpaceEnglish
Detect the lack of space between English text and inline math in .tex and .md files.

Skip the target token if it follows "th" (e.g.,
\(n\)th) or is followed by a command (e.g., $\backslash$n).
LLSpaceJapanese
Detect the lack of space between Japanese characters and math equations in .tex and .md files.
This rule is disabled by default.
LLT
Detect ^T in .tex and .md files.
You likely want to use ^\top or ^\mathsf{T} instead to represent the transpose of a matrix or a vector.
This rule is disabled by default.
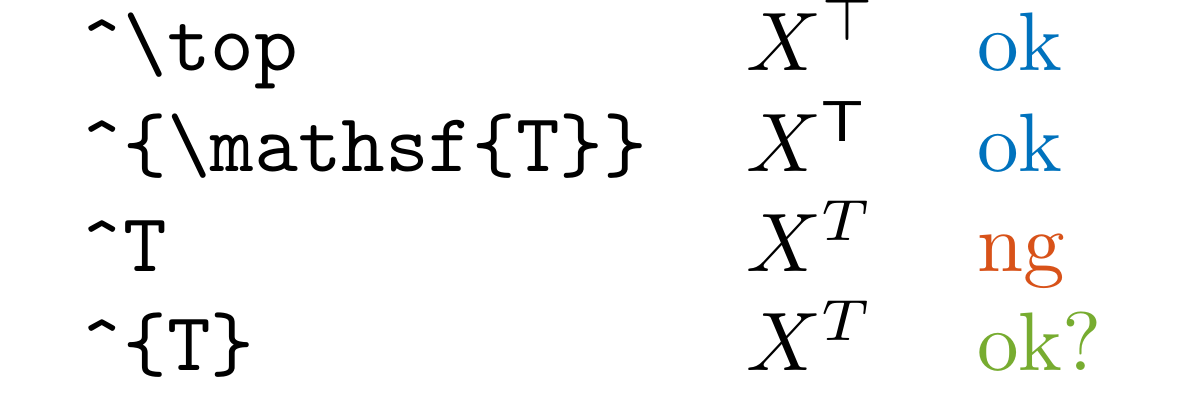
Otherwise, we cannot distinguish between the transpose and the power by a variable T (you can use ^{T} for the power).
We also do not detect \sum_{i=1}^T or \prod_{i=1}^T as errors.
References:
What is the best symbol for vector/matrix transpose? (Stack Exchange)
LLTextLint
Detect dubious text in .tex and .md files.
In web version, we use some of the proofreading rules used in the open source textlint to detect some errors. Currently, only Japanese text is checked.
In the VS Code version, we mainly use some pattern matching to detect text that is likely to be incorrect.
LLThousands
Detect wrongly used commas as thousands separators, such as 1,000 in .tex files.
You should likely use 1{,}000 or use the package icomma.
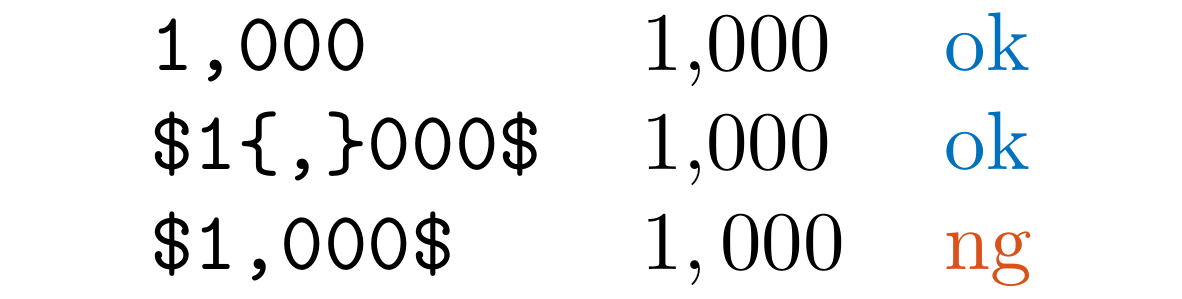
References:
avoid space after commas used as thousands separator in math mode (Stack Exchange)
LLTitle
Detect dubious title cases in \title{}, \section{}, \subsection{}, \subsubsection{}, \paragraph{}, and \subparagraph{} in .tex files.
For example,
The quick brown fox jumps over the lazy dog
should be
The Quick Brown Fox Jumps Over the Lazy Dog
in the title case. We detect such cases.
It is very difficult to detect all non-title cases because of the many exceptions and styles. We highly recommend using Title Case Converter or Capitalize My Title to convert the title in your preferred style.
We test the string inside the {} is invariant by the function toTitleCase implemented based on to-title-case, JavaScript library. There might be some false positives and negatives.
References:
Title Case Capitalization (APA Style)
LLUnRef
Detect \label{...} in figure and table environments that are never referenced by \ref{...} or \cref{...} in .tex files.
This rule only detects unreferenced labels if they are already present in the figure. It does not detect the absence of labels in the first place.
If a file has no LaTeX preamble, this rule skips files that consist only of table / table* environments.
Requiring all figures and tables to be explicitly referenced in the text may feel a bit unnatural, as it differs from common practice in general media. However, in academic writing, it is actually required by many style guides and journals. For more details, please see the references. As an example, here is a quote from the APA 7th Edition style guide:
General guidelines
All figures and tables must be mentioned in the text (a "callout") by their number. Do not refer to the table/figure using either "the table above" or "the figure below."
(Citing tables, figures & images: APA (7th ed.) citation guide)
References:
Is it normal to require to reference all figures and tables in the text? (Academia Stack Exchange)
LLURL
Detect URLs containing query strings in .tex and .md files.
The following query strings are considered unnecessary:
The other query strings are allowed:
?user=... (e.g., Google Scholar profile URLs)?q=... (e.g., search queries)?page=...?lang=...
LLUserDefined
You can define your own regular expressions to detect in .tex and .md files.
Check LaTeX Lint: Add Custom Detection Rule for more details.
We listed some examples in the following.
Example 1: Use mathrm for English letters
When you use English letters in math mode for an explanation, consider using \mathrm.
For example, if the character a is not a variable and represents something like atractive force, consider writing f^a(x) as f^{\mathrm{a}}(x).
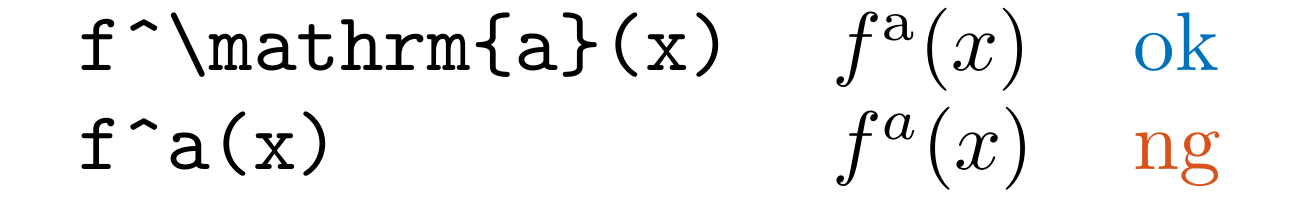
However, it is difficult to detect without context. You can define the rule f\^a to detect this pattern.
Example 2: Use appropriately defined operators
When you use operators, you should use \DeclareMathOperator.
For example, if you use \Box as an infimal convolution, you should define it as an operator.
\DeclareMathOperator{\infConv}{\Box}
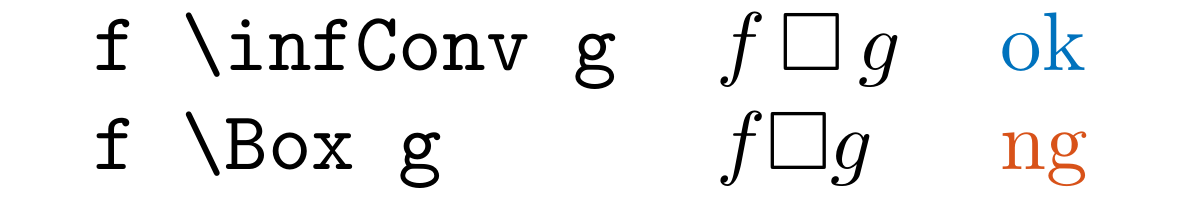
Then, you can use \infConv instead of \Box, and you can define \\Box as a regular expression to detect this pattern.
Command Palette
In VS Code, you can run commands by clicking the icon or by opening the command palette (Ctrl+Shift+P) and typing LaTeX Lint.
The following sections explain some commands.
LaTeX Lint: Add Custom Detection Rule
Add a custom detection rule.
For example, we can detect f^a by the following steps.
- Select the string you want to detect (optional).
- Run the Add Custom Detection Rule command.
- Follow the instructions.
If you choose
string, we detect the input itself.
If you choose Regex, we detect the pattern using a regular expression.
Then, you can define your own rule.
In the web version, you can add regular expressions in the User defined Regex rules input box at the bottom of the page.
LaTeX Lint: Choose Detection Rules
Select which rules to detect. Check the rules you want to detect.
In the web version, you can turn individual rules off using the Disabled rules checkboxes at the bottom of the page.
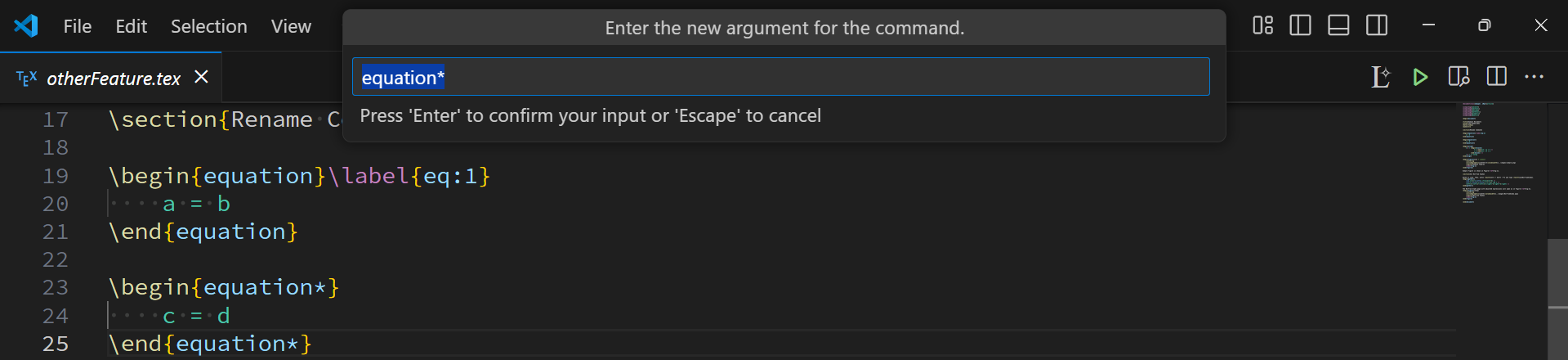
LaTeX Lint: Rename Command or Label
Rename by pressing F2 on the \begin{name}, \end{name} or \label{name}.
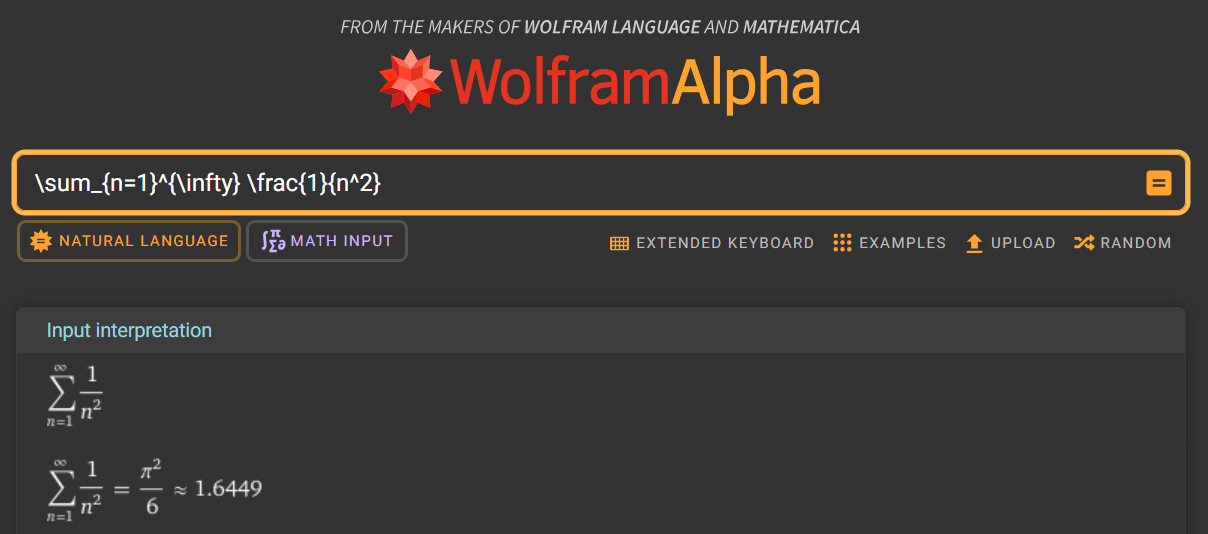
LaTeX Lint: Query Wolfram Alpha
Query Wolfram Alpha to solve the equation.
- Select the equation you want to solve.
- Run the Query Wolfram Alpha command.
- Check the Wolfram Alpha page.
You can see the result on the Wolfram Alpha page. Some unnecessary commands are removed before the equation is sent.
Disabling Rules
LLDisable
To disable a rule, add % LLDisable at the beginning of the line for LaTeX or <!-- LLDisable --> for Markdown.
Line containing an error. % LLDisable
Line containing an error. <!-- LLDisable -->
To toggle the entire rule on or off, use LaTeX Lint: Choose Detection Rules.
LaTeX Lint: Add Exception Word
Add an exception word to suppress detections for a specific word.
- Select the word you want to add as an exception (optional).
- Run the Add Exception Word command.
- Follow the instructions. Then, the word is added to the exception list and will be ignored by supported rules.
In the web version, you can also add an exception word by filling in the input box at the bottom of the page.
Note
As stated in the Rules, false positives and false negatives may occur. We welcome any kind of feedback, suggestions, and pull requests.
When writing papers, please ensure you follow the style specified by the academic society or publisher.
We hope this extension will be helpful for your academic writing.
License
This project consists of multiple components with different licenses:
Main Extension
Licensed under the MIT License.
See LICENSE file for details.
(The library to-title-case is also under MIT License.)
Web Component (latexpages repository)
Licensed under the Apache License 2.0.
See the latexpages repository for details.
The web component includes code from:
- textlint (MIT License)
- kuromoji.js (Apache License 2.0)
Acknowledgement
Although we do not use them directly, part of our extension is inspired by the following excellent LaTeX checking tools:
- LaTeX package chktex (GNU General Public License, version 2 or newer)
- Linter for LaTeX latexcheck (MIT License)
Additionally, our extension also resembles the following VS Code extensions in some features:
We sincerely appreciate the developers of these tools.