Hex Viewer
Custom editor extension to open files in raw byte representation. Also renders possible text decoding results. Doesn't support editing the document (yet).
Features
- Select decoder to render textual data
- Supports multibyte encodings
- Custom decoder scripts (not supported in virtual workspaces)
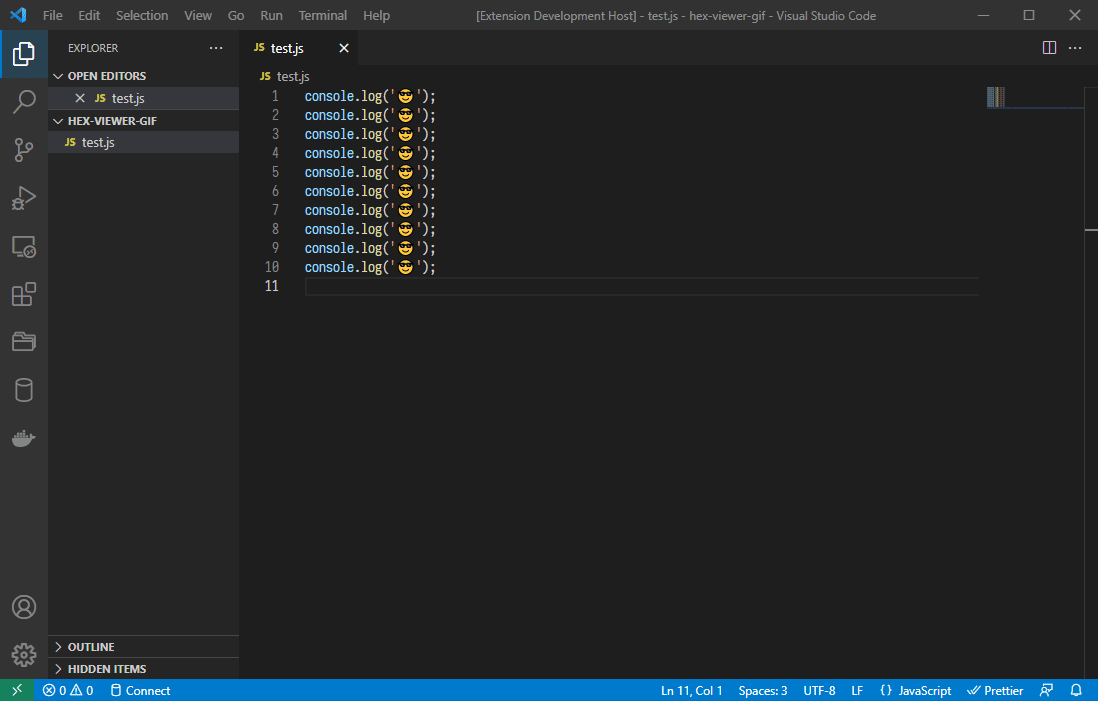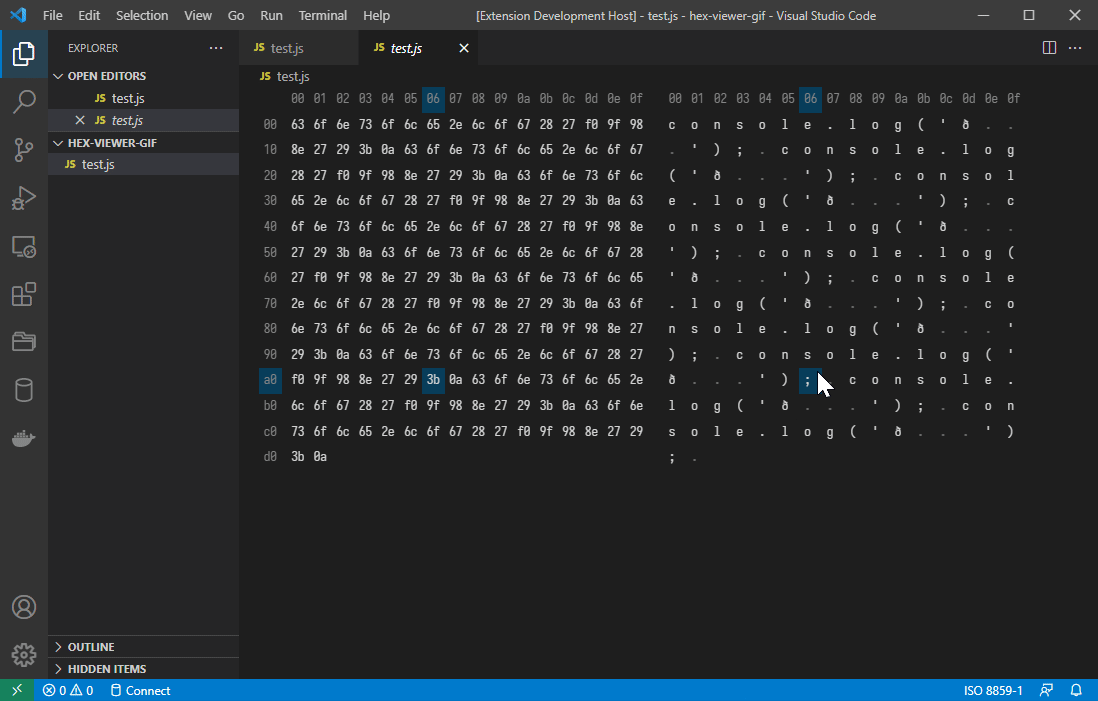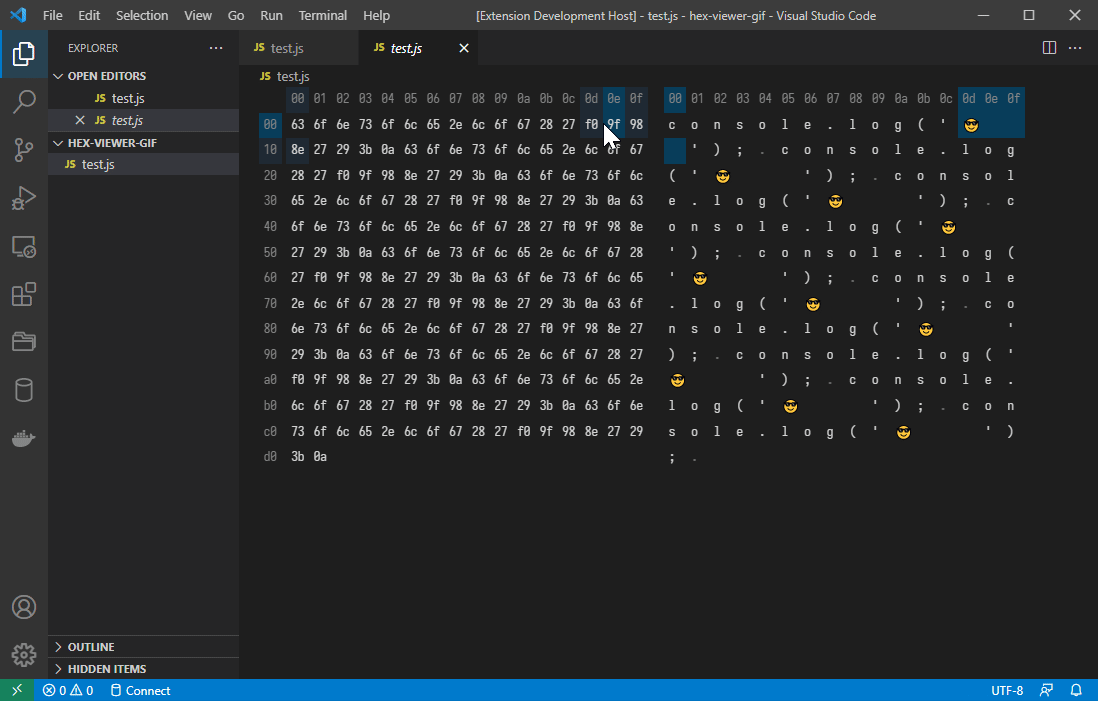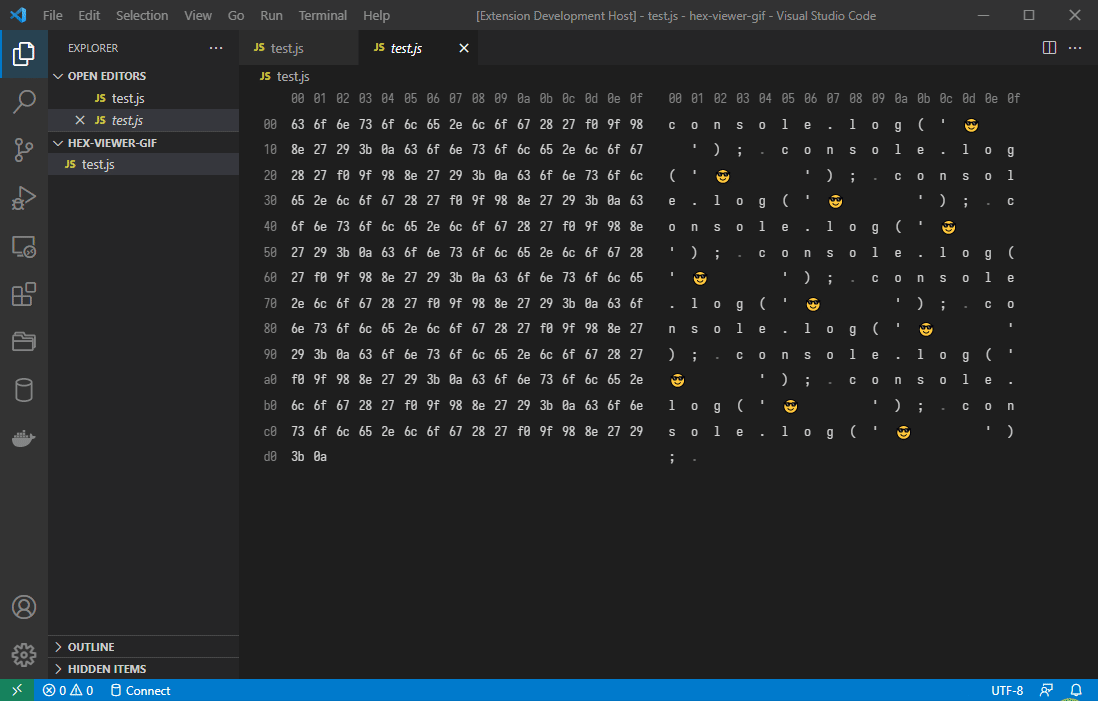
Builtin decoders
The extension implements builtin decoders for standard text encodings. The following decoders are currently implemented:
- ASCII (default)
- ISO 8859-1
- UTF-8
- UTF-16
- UTF-32
Decoders for multibyte encodings like UTF-8 will skip invalid byte sequences and render the skipped bytes with an error color.
Implementing a custom decoder
Custom decoder scripts are currently only supported in non-virtual workspaces. The decoder script should be a CommonJS script that exports a single function. The function should adhere to the Decoder type in the definitions below:
type DecodedValue =
| null // undecoded single byte, rendered as dot with weaker text color
| string // decoded single byte
| {
// can be used for multibyte sequences
// or for single byte values that should be rendered in a specific color
text?: string; // treated like null above if not specified
length?: number; // length of the byte sequence, defaults to 1
style?: {
color?: string; // valid CSS color string, can also be a CSS variable defined by VS Code for theming
};
};
type RenderControlCharacters = 'hex' | 'abbreviation' | 'escape' | 'caret' | 'picture';
interface DecoderConfig = {
fileUri: string;
settings: {
renderControlCharacters: 'off' | RenderControlCharacters | RenderControlCharacters[];
};
};
type Decoder = (data: Buffer, config: DecoderConfig) => DecodedValue[];
When the custom decoder supports multibyte sequences, the result array likely won't be of the same length as the source data. The sum of single and multibyte decodings shouldn't exceed the source data length. If the sum is less than the source data length, the result will be padded with null to match the source data length. Custom scripts are not sandboxed as VS Code extensions aren't either. The script's working dir is the workspace it is in or relative to the script itself if it is outside the workspace (specified by an absolute path).
Below is a sample decoder, that simply renders the numeric value of each byte in its decimal form:
module.exports = (data) => [...data].map((byte) => `${byte}`);
:warning: Typically a decoded text unit is a single character but it doesn't have to be. The extension can render strings of arbitrary length for a single byte, the CSS grid layout makes sure the columns will align. With that said, strings that exceed two or three characters will likely distort the layout in unpleasant ways.
To use a custom decoder it has to be registered in the settings. The configuration entry point is hexViewer.customDecoders and is an object lists key/value pairs, where the key is the name for the decoder and the value is the path to the script file. Relative paths are resolved from the workspace root.
Configuration
hexViewer.customDecoders
Map of custom decoders. Keys are decoder names and values are the path to the JS file. Relative paths are resolved from the workspace root.
{
"type": "object",
"additionalProperties": {
"type": "string"
},
"default": {},
}
hexViewer.decode.renderControlCharacters
Render control characters with a graphical representation. Supports multiple options for choosing a representation. If specified as an array of options, the oprionts are evaluated from left to right in descending priority (not all options cover all the control characters). Possible representations can be seen on Wikipedia. The hex option is the only one that also covers C1 control codes.
{
"oneOf": [
{
"type": "string",
"enum": [
"off",
"hex",
"abbreviation",
"escape",
"caret",
"picture"
]
},
{
"type": "array",
"items": {
"type": "string",
"enum": [
"hex",
"abbreviation",
"escape",
"caret",
"picture"
]
},
"minItems": 1,
"uniqueItems": true
}
],
"default": "off",
}
Possible future enhancements
These are just ideas that may or may not happen:
- more builtin decoders for standard text encodings like Windows 1252
- async decoders
- make default decoder configurable for file patterns
- go to offset
- data inspection
- display unicode information for decoded text
- find byte sequences / decoded text
- make case of hexadecimal letters configurable
- configuration for rendering whitespace and other invisible unicode characters
- configurable offset width
- editing documents