Interactive SQL and PySpark Notebooks | Powered by DuckDB
📝 Table of Contents
🧐 About
DuckLab for VS Code provides data analysis features for SQL, PySpark and Python. It uses DuckDB to process your data locally.
🔥 Features
- Run SQL and Python in the same notebook using same duckdb instance (exposed as
db variable in python)
- Ducklab Spark Kernel allows running pyspark code using
duckdb.experimental.spark module (exposed as spark, a SparkSession instance).
- Import Databricks
.py notebooks and preview in a user-friendly VS Code Notebook window.
- Use any python, venv or conda environment detected by VS Code Python extension.
- Git-friendly
.isql format. This format is plain text and human readable.
- Ducklab doesn't use
ipynb format which stores cell outputs in the file and pollutes git. It also makes diff in pull requests unreadable.
- Cell magics for convenience.
🏁 Getting Started
Using Ducklab SQL Kernel (no dependencies required)
- Create a new
.isql file.
- Select kernel
SQL Only
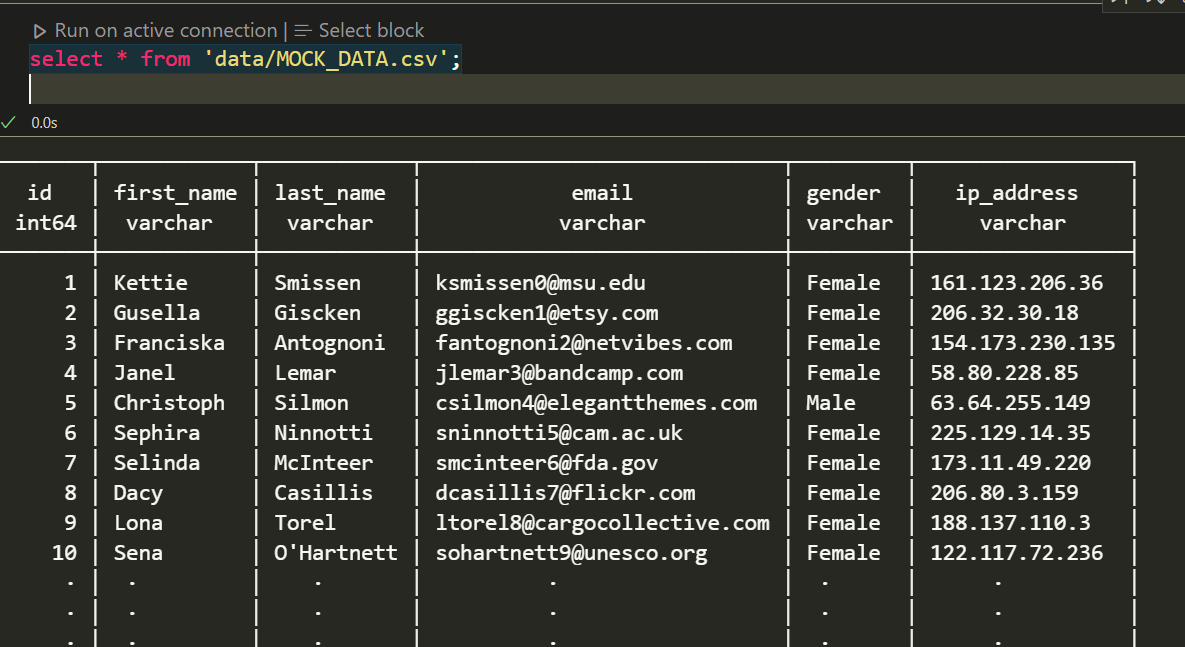
- Run SQL queries e.g.
select * from 'data/MOCK_DATA.csv';
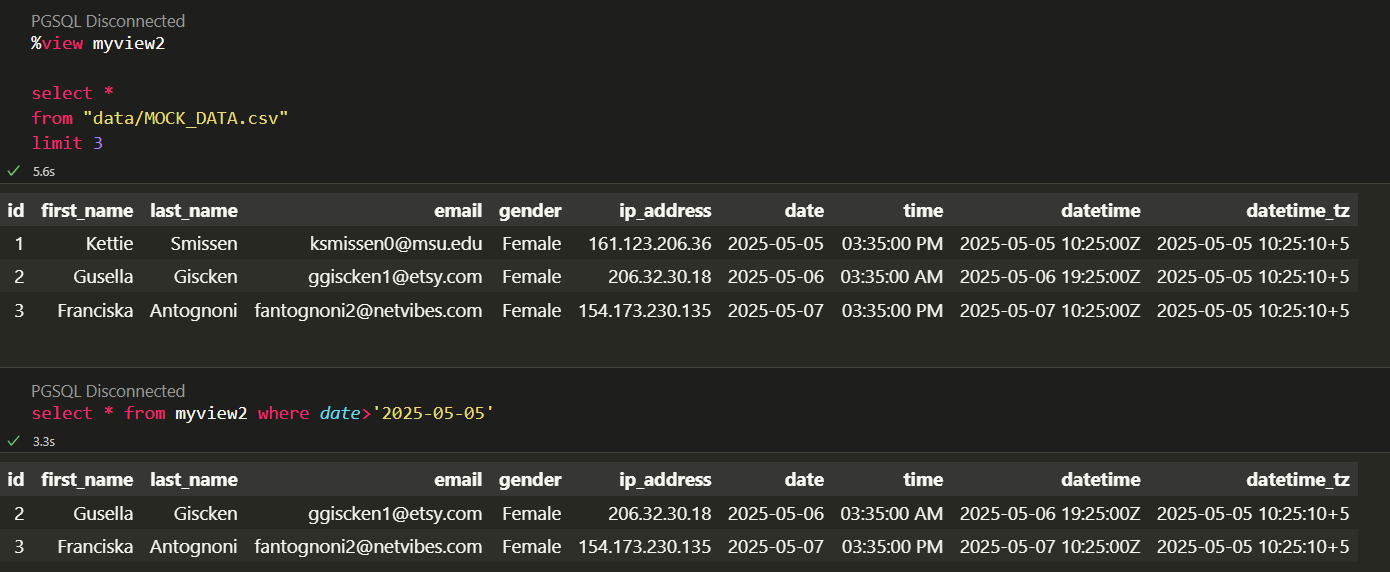
Using Cell Magics
- Use '%view myview' cell magic to create a view from your SELECT query and preview the results.
Using Ducklab Python Kernel
- Make sure python or Anaconda is installed.
- Create a new
.isql file.
- Select kernel
Python/SQL
- Select Python environment from bottom-right corner
ducklab-python kernel will have db variable (duckdb connection) already initialized for you.- Run python or SQL code
Using Ducklab Spark Kernel
- Make sure python or Anaconda is installed.
- Create a new
.isql file.
- Select kernel
PySpark/SQL
- Select Python environment from bottom-right corner
ducklab-spark kernel will have spark variable (SparkSession) already initialized for you.- Run spark code,
import pandas as pd
from duckdb.experimental.spark.sql.functions import lit, col
pandas_df = pd.DataFrame({
'age': [34, 45, 23, 56],
'name': ['Joan', 'Peter', 'John', 'Bob']
})
df = spark.createDataFrame(pandas_df)
df = df.withColumn(
'location', lit('Seattle')
)
df = df.select(
col('age'),
col('location')
)
display(df)
Import Databricks Notebook
- Right click on a Databricks
.py notebook file
- Click
Import Databricks Notebook
💬 Contribute
Contributions are most welcome. There are various ways you can contribute,
Implement a new feature
- Create an issue and provide your reasoning on why you want to add this feature.
- Discuss your approach and design.
- Implement the feature and submit your PR.
Request a new feature
- Open an issue and provide details about your feature request.
- In case other tools implement that functionality then it will be helpful to share the reference for inspiration and design.
Fix a bug
- If you are resolving an issue, please add fix: # in your PR title (e.g.fix: #3899 update entities encoding/decoding).
- Provide a short description of the bug in your PR and/or link to the issue.
🎉 Acknowledgements
- DuckDb - In-process analytics database
| |

