Spark & Hive Tools for VSCode - an extension for developing PySpark Interactive Query, PySpark Batch, Hive Interactive Query and Hive Batch Job against Microsoft HDInsight, SQL Server Big Data Cluster, and generic Spark clusters with Livy endpoint! This extension provides you a cross-platform, light-weight, keyboard-focused authoring experience for Spark & Hive development.
Prerequisites:
Quick Start:
Spark & Hive Tools for VSCode will only be activated when you either create a new .py/.hql/.hive File or open an existing .py/.hql/.hive file.
You can activate Azure Spark & Hive Tools for VSCode via creating a new .py/.hql/.hive File or opening an existing .py/.hql/.hive file.
Open a work folder
From Visual Studio Code, Click the File menu, and then click Open Folder.
Specify or Create a new folder, and then click Select Folder.
Click the New File under your created work folder, or click the File menu, and then click New File. An Untilted-1 file is shown in the right pane.
Connect to a Spark or Hive Cluster
We provide two ways to manage your cluster: Connect to Azure (Azure: Login) and Link a Cluster
Connect to Azure (Azure: Login)
Before you can submit scripts to your cluster, you need connect to your Azure account or link your cluster.
Create a new work folder and a new script file if you don't have one.
Right-click a hive script editor, and then click Azure: Login. You can also use another way of pressing CTRL+SHIFT+P and entering Azure: Login.
![Spark & Hive Tools for Visual Studio Code log in]
To sign in, follow the sign-in instructions in the OUTPUT pane.
- For Azure global environment, Azure: Login command will trigger Sign in to Azure action in the HDInsight explorer and vice versa.
![Spark & Hive Tools for Visual Studio Code global login info]
- For Other environments, follow the sign-in instructions.
![Spark & Hive Tools for Visual Studio Code other login info]
Follow the instructions to sign in from the web page. Once connected, your Azure account name is shown on the status bar at the left-bottom of the VSCode window.
[!NOTE]
If your account has two factors enabled, it is recommended to use phone authentication instead of Pin.
There is an known issue about Azure login. Recommend using Chrome.
Link a cluster
You can link a normal cluster by using Ambari managed username, also link a security hadoop cluster by using domain username (such as: user1@contoso.com).
Open the command palette by selecting CTRL+SHIFT+P, and then enter Big Data: Link a cluster.
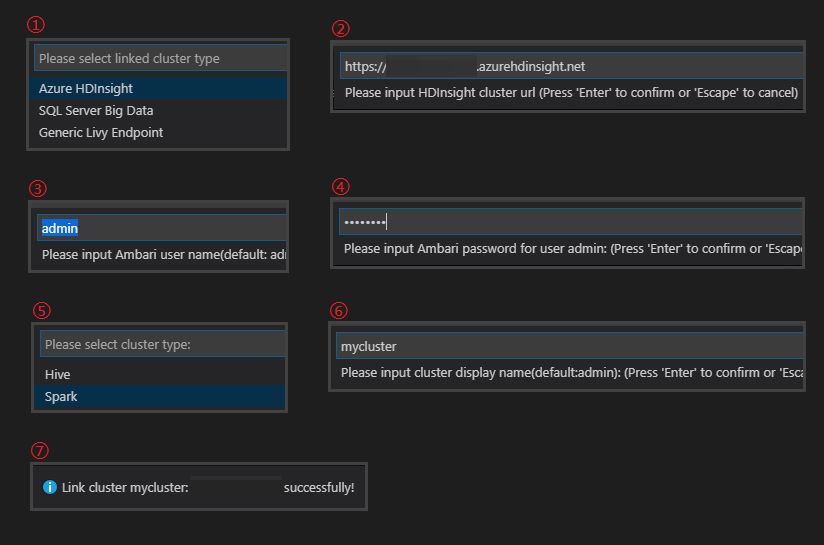
Select linked cluster type -> Enter cluster URL -> input Username -> input Password -> select cluster type -> Input cluster display name(optional)-> it shows success info if verification passed.
[!NOTE]
We use the linked username and password if the cluster both logged in Azure subscription and Linked a cluster.
You can see a Linked cluster by using command Spark / Hive: List cluster. Now you can submit a script to this linked cluster.

You also can unlink a cluster by inputing Spark / Hive: Unlink a cluster from command palette.
Submit interactive PySpark queries
Spark & Hive Tools for VSCode also enable you to submit interactive PySpark queries to Spark clusters.
Create a new work folder and a new script file with the .py extension if you don't have one.
Connect to your Azure account, if you haven't done so.
Copy and paste the following code into the script file:
from operator import add
lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0])
counters = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
coll = counters.collect()
sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True)
for i in range(0, 5):
print(sortedCollection[i])
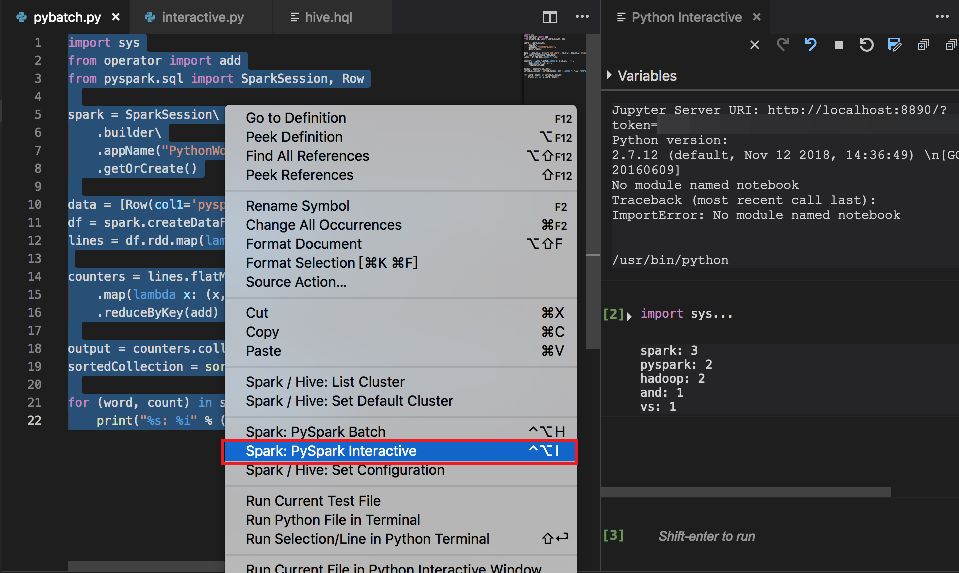
Highlight these scripts and right-click the script editor, then click Spark: PySpark Interactive.
Set up python environment if you don't install it. The instruction, see Set Up PySpark Interactive Environment for Visual Studio Code.
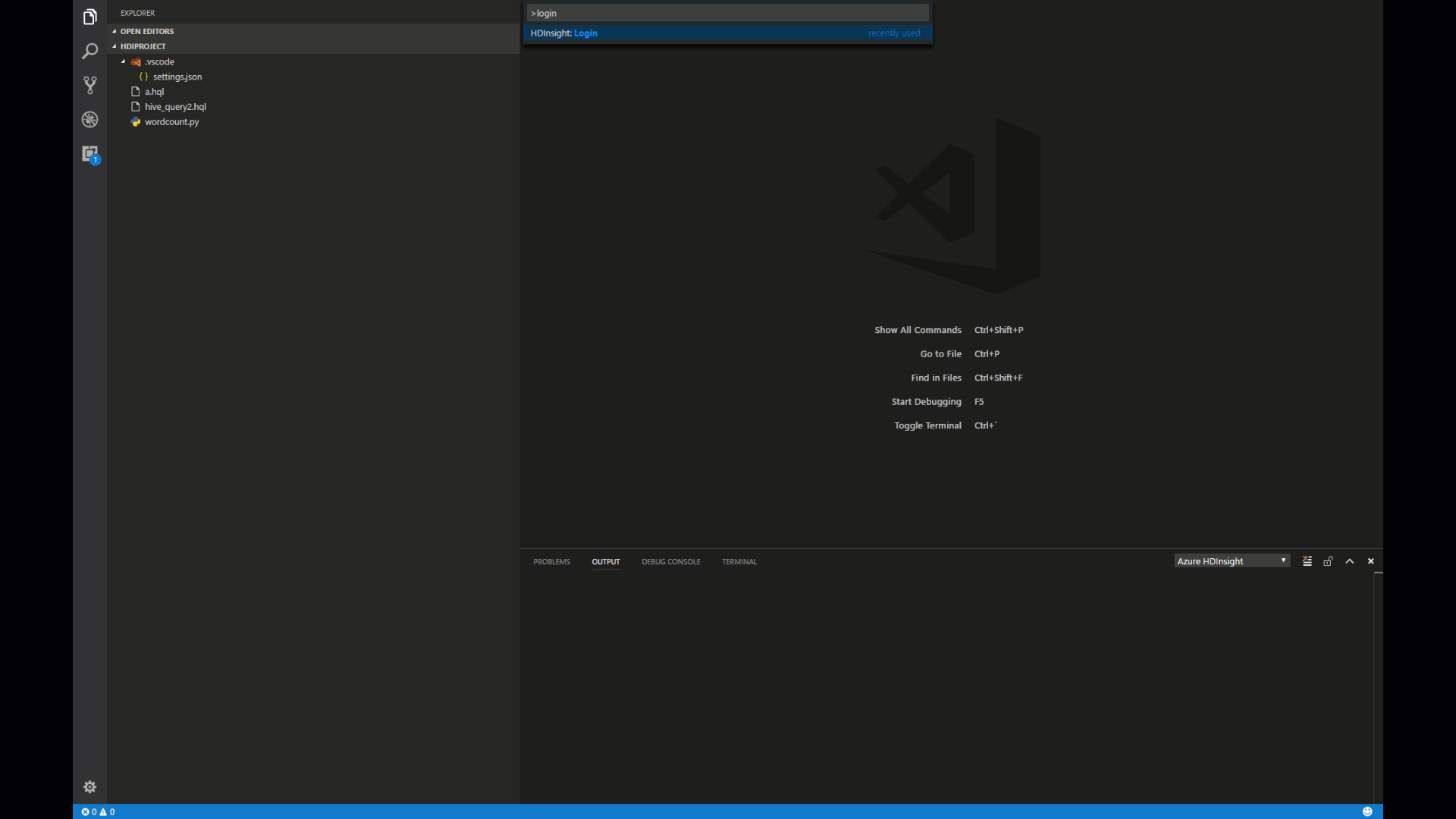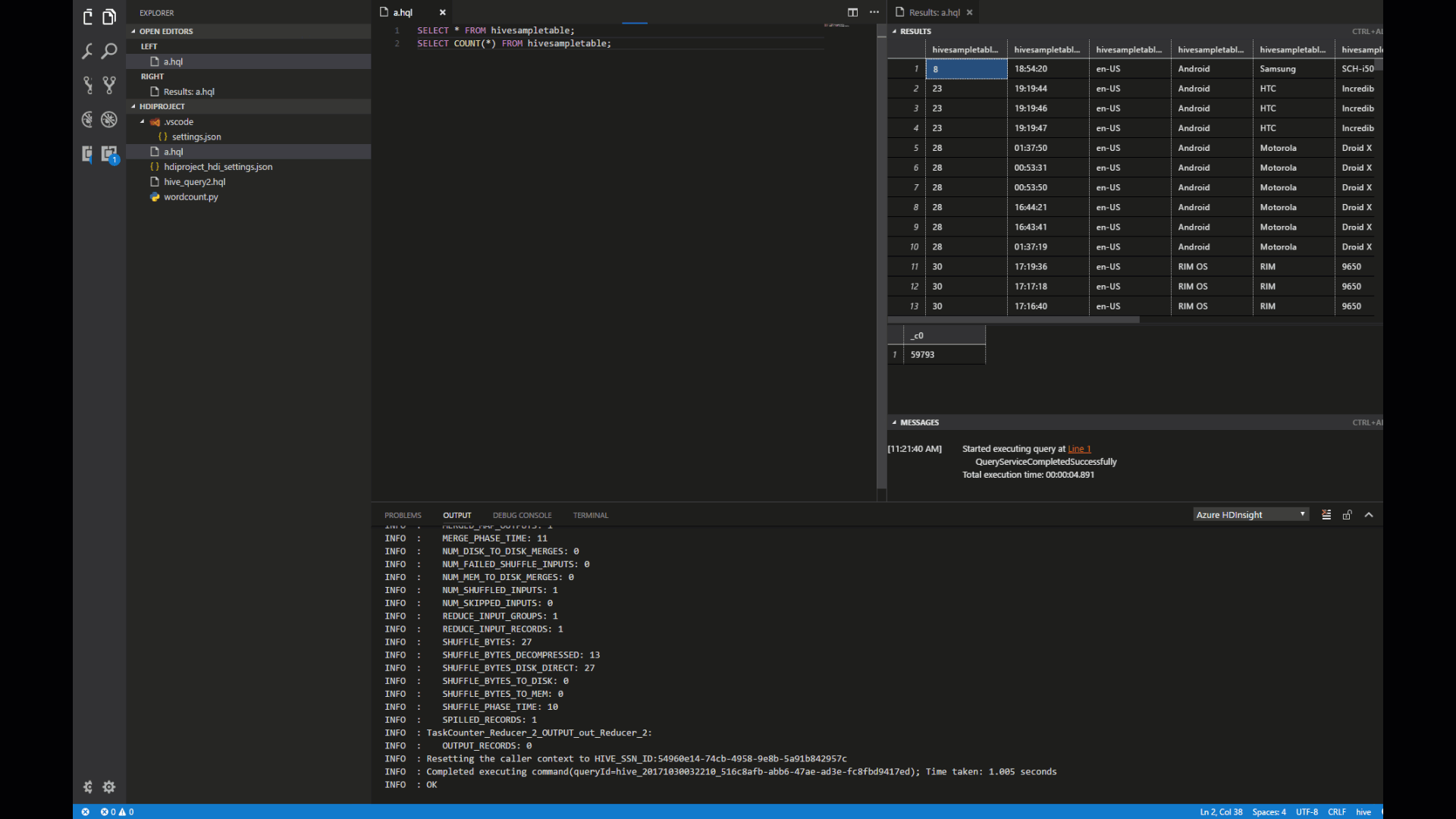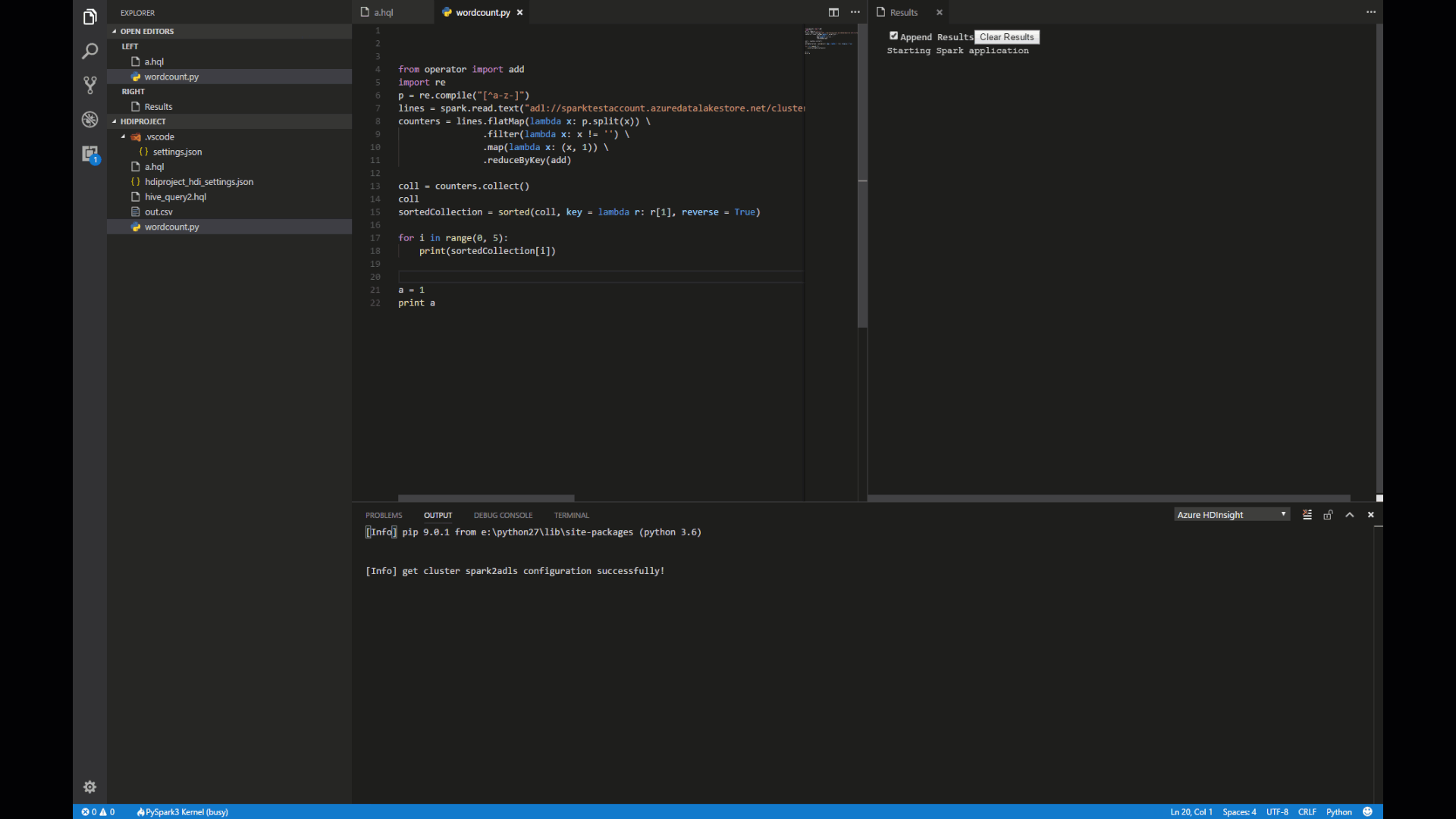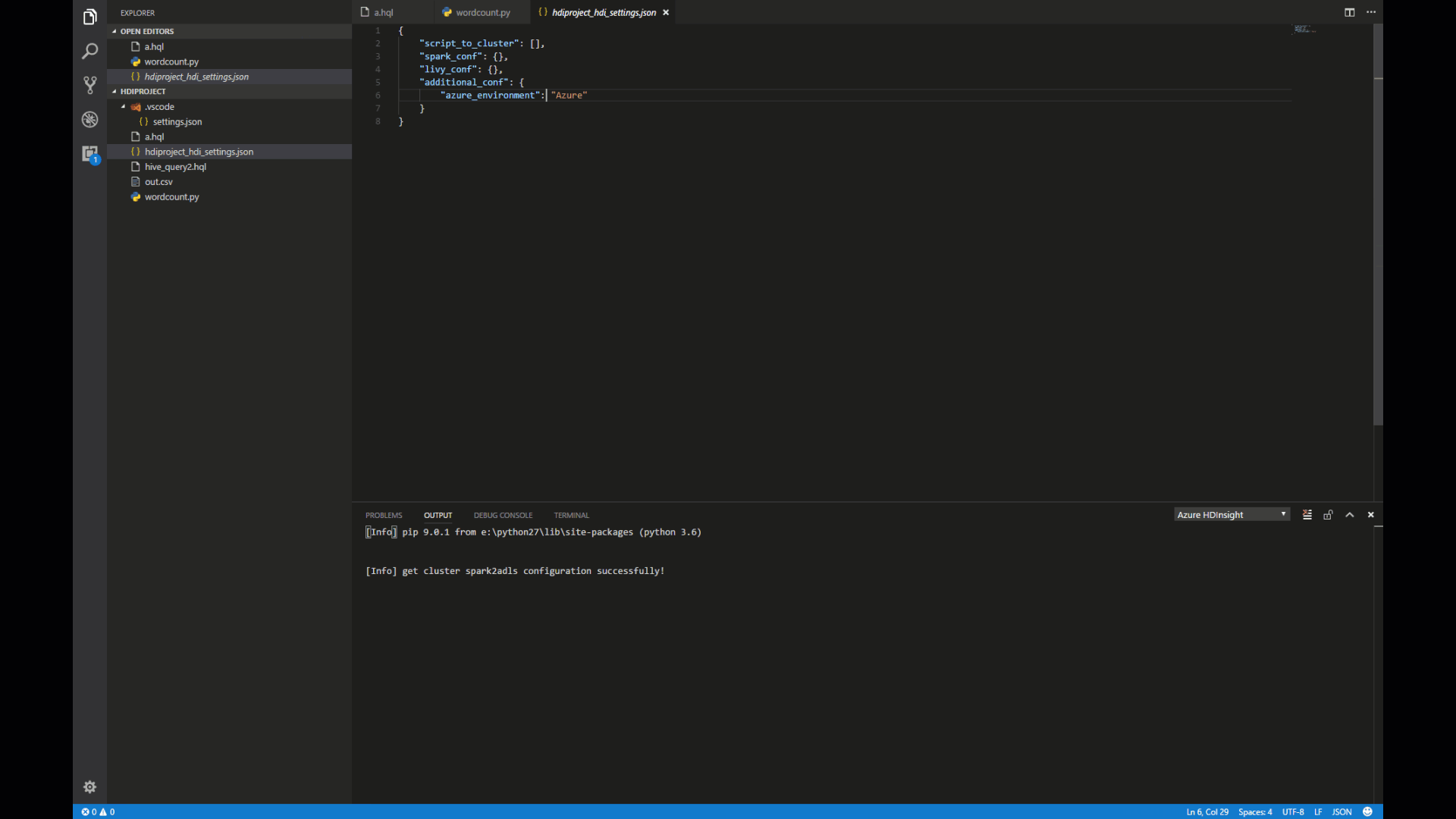
Select a cluster to submit your PySpark query. Soon after, the query result is shown in the right new tab:
Our tool also supports query the SQL Clause.
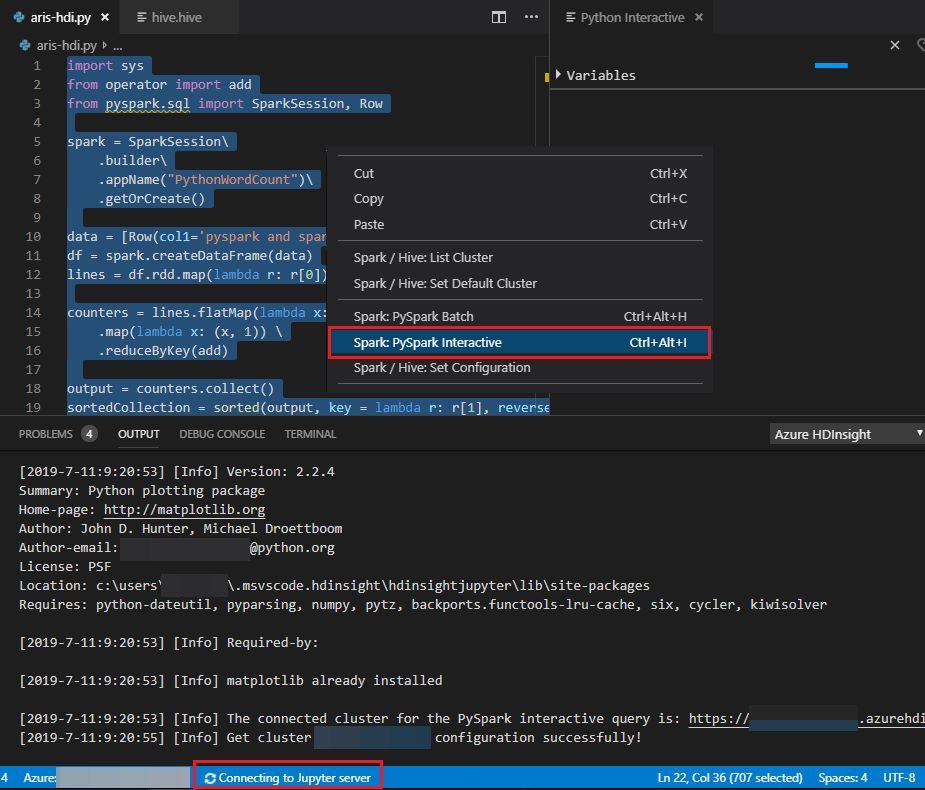 The submission status appears on the left of the bottom status bar when you're running queries.
The submission status appears on the left of the bottom status bar when you're running queries.
Our clusters can maintain a session. For example, a=100, already keep this session in cluster, now you only run print a to cluster.
Submit PySpark Batch job
Create a file in your current folder and named xxx.py.
Copy and paste the following code into xxx.py, then save it.
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' '))\
.map(lambda x: (x, 1))\
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()
Right-click a py script editor, and then click Spark: PySpark Batch. You can also use another way of pressing CTRL+SHIFT+P and entering Spark: PySpark Batch.
Select a cluster to submit your PySpark job.
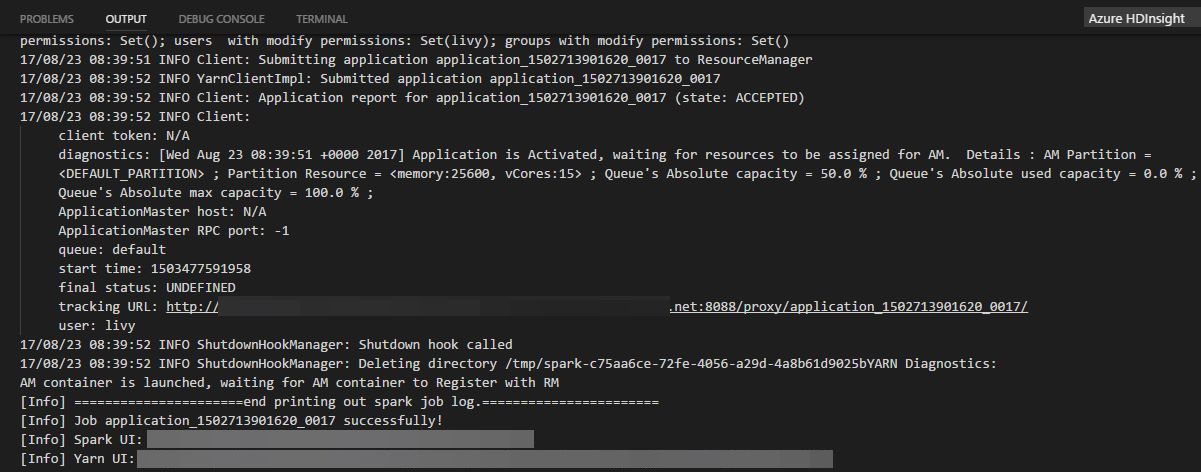
After submitting a python job, submission logs is shown in OUTPUT window in VSCode. The Spark UI URL and Yarn UI URL are shown as well. You can open the URL in a web browser to track the job status.
Hive Interactive
Spark & Hive tool for VSCode enables you to submit interactive Hive query to a Hive cluster Hive Interactive cluster and displays query results.
Create a file in your current folder and named xxx.hql or xxx.hive.
Copy and paste the following code into your hive file, then save it.
SELECT * FROM hivesampletable;
Right-click a hive script editor, and then click Hive: Interactive to query the result quickly. You can also use another way of pressing CTRL+SHIFT+P and entering HIve: Interactive.
Our tool also supports that selects a few lines of script, and submit by context menu.
Select cluster that support **Hive Interactive ** (LLAP) to submit your query. Soon after, the query result tab is shown on the left.
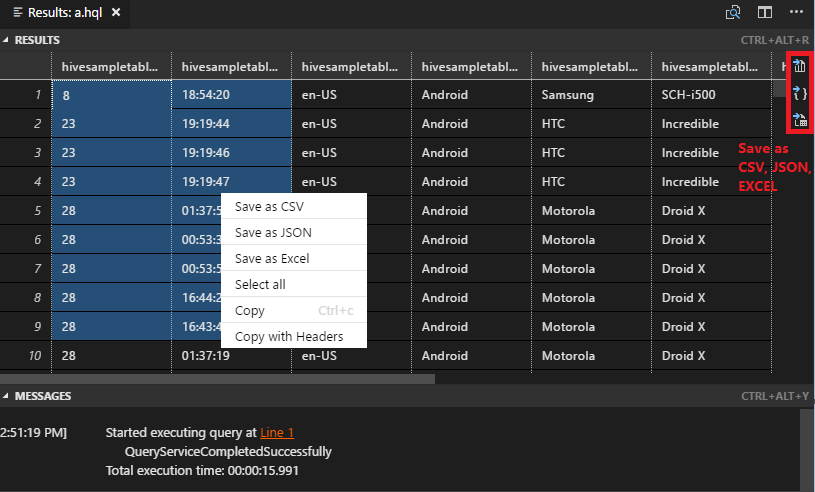
- RESULTS panel: You can save the whole result as CSV,JSON,EXCEL to local path, or just select multiple lines.
- MESSAGES panel: Clicking Line number, it jumps to the first line of the running script.
Submit Hive batch script
Create a file in your current folder and named xxx.hql or xxx.hive.
Copy and paste the following code into your hive file, then save it.
SELECT * FROM hivesampletable;
Right-click a hive script editor, and then click Hive: Batch to submit a hive job. You can also use another way of pressing CTRL+SHIFT+P and entering Hive: Batch.
Select a cluster to submit your Hive Script. And Make sure the hivesampletable is already exists in your cluster.
- RESULTS panel: You can save the whole result as CSV,JSON,EXCEL to local path, or just select multiple lines.
- MESSAGES panel: Clicking Line number, it jumps to the first line of the running script.
List Spark & Hive clusters
To test the connection, you can list your Spark and Hive clusters:
To list your clusters under your Azure subscription
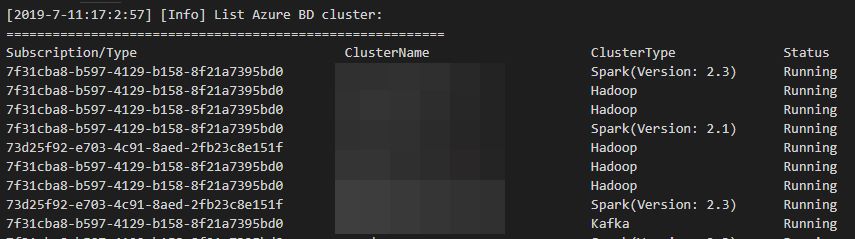
Right-click a hive script editor, and then click Spark/Hive: List Cluster. You can also use another way of pressing CTRL+SHIFT+P and entering Spark/Hive: List Cluster.
The hive and spark clusters appear in the Output pane.
Set default cluster
Right-click a hive script editor, and then click Spark/Hive: Set Default Cluster. You can also use another way of pressing CTRL+SHIFT+P and entering Spark/Hive: Set Default Cluster.
Select a cluster as default cluster for the current script file.
Meanwhile, our tool already saved what you selected default clusters into XXXX_hdi_settings.json. You also directly update it in this configuration file.
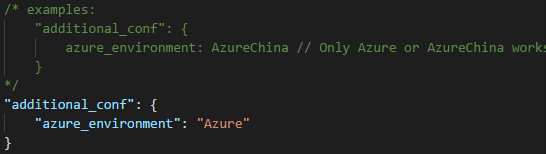
Set Azure environment
Select File > Preferences > Settings. A new tab will open in VSCode labeled User Settings
Go to VSCode Settings, search by Azure: Cloud.
Select one way from Azure and AzureChina as your default login entry.
Additional features
The Spark & Hive for VSCode supports the following features:
IntelliSense auto-complete. Suggestions are popped up around keyword, method, variables, etc. Different icons represent different types of the objects:
![Spark & Hive Tools for Visual Studio Code IntelliSense object types]
IntelliSense error marker. The language service underlines the editing errors for hive script.
Syntax highlights. The language service uses different color to differentiate variables, keywords, data type, functions, etc.
![Spark & Hive Tools for Visual Studio Code syntax highlights]
Document of Spark & Hive for VScode
License
| |
