CodexMicroORMAn alternative to ORM's such as Entity Framework, offers database mapping for your existing CLR objects with minimal effort. CodexMicroORM excels at performance and flexibility as we explain further below. Product not a fit for you? Feel free to visit and learn about data integration and ORM concepts through our blog and product updates. Refer to our recent article that covers recent updates in the 0.5 release. BackgroundWhy build a new ORM framework? After all, Entity Framework, nHibernate and plenty of others exist and are mature. I have seen complaints expressed by many, though: they can be "heavy," "bloated" and as much as we'd like them to be "unobtrusive" - sometimes they are. Wouldn't it be nice if we could simply use our existing POCO (plain-old C# objects) and have them become ORM-aware? That's the ultimate design goal of CodexMicroORM: to give a similar vibe to what we got with "LINQ to Objects" several years ago. (Recall: that turned anything that was IEnumerable<T> into a fully LINQ-enabled list source - which opened up a whole new world of possibility!) CodexMicroORM (aka "CEF" or "Codex Entity Framework") isn't necessarily going to do everything that other, larger ORM frameworks can do - that's the "micro" aspect. We'll leave some work to the framework user, favoring performance much of the time. That said, we do aim for simplicity as I hope the demo application illustrates. As one example, we can create a sample Person record in one line of code: The demo project and tests show several other non-trivial use cases. The work done with CodexMicroORM leads naturally into some related tool work, including a HybirdSQL database add-on, where the goal is to remove the need to worry about object-relational mapping: as an object-oriented database, it will offer excellent in-memory performance with greater simplicity than many other alternatives. Follow this project to stay on top of details! Design GoalsDiving more deeply, what does CodexMicroORM try to do better than other frameworks? What are the guiding principles that have influenced it to date? (Too much detail if you're skimming? Feel free to skip forward, but check back here from time to time as this list will be updated to reflect any new base concepts that CEF will address.)
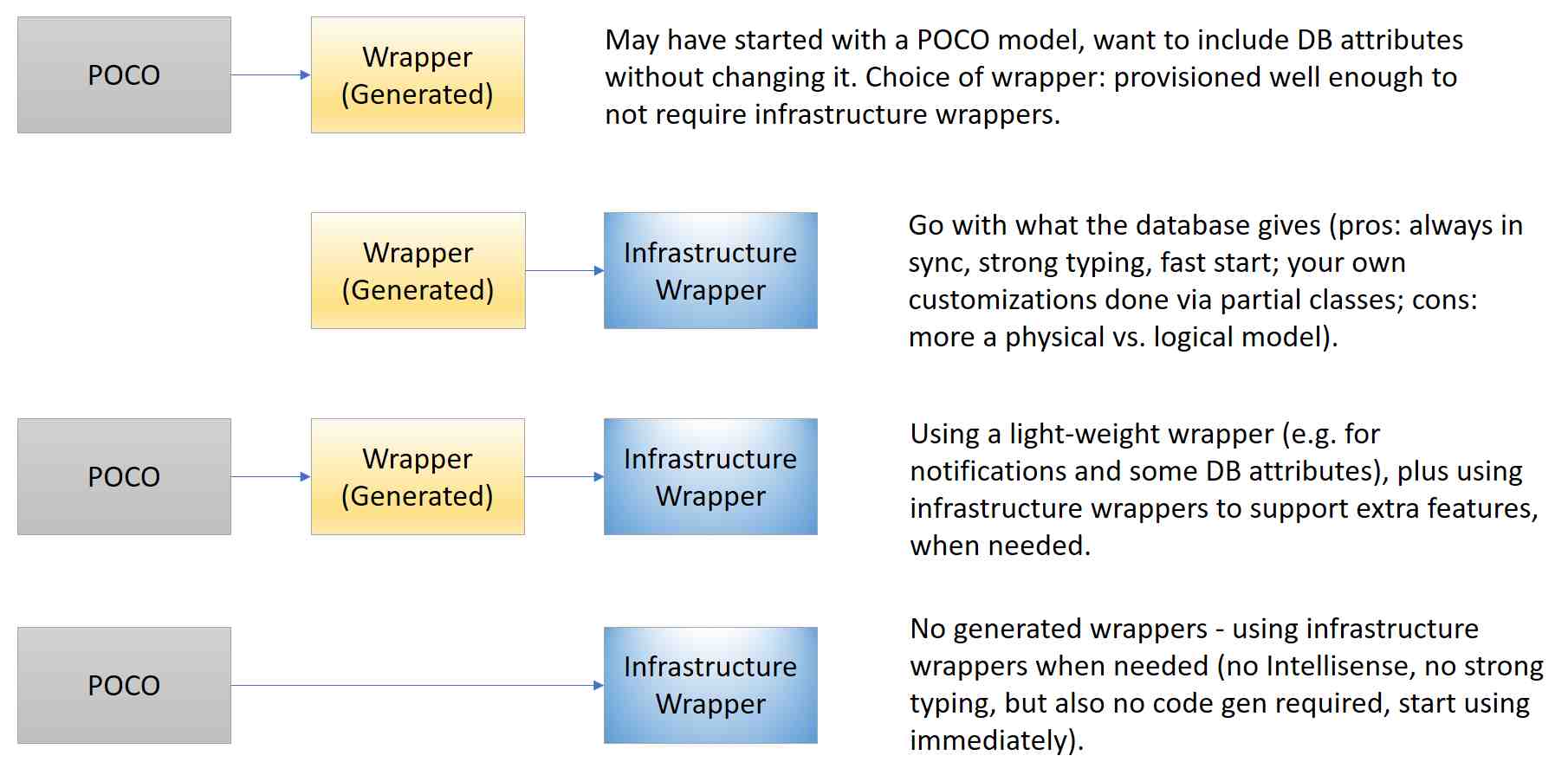
I'll dive deeper on the various design goals in blog postings. General ArchitectureThe general approach of CodexMicroORM is to wrap objects - typically your POCO. Why? We make no assumptions about what services your POCO may provide. In order to have an effective framework, one handy interface we want to leverage is INotifyPropertyChanged. If your POCO do not implement this, we use a wrapper that does and use containment with your POCO - wrapping it. (Update 0.2.4: in this release we add support for IDataErrorInfo as an interface exposed by CEF wrappers - see below for an example of its usage in WPF.) The concept of a context isn't unfamiliar to many ORM frameworks. CodexMicroORM also uses the idea of a context, but is called the service scope. A service scope is unobtrusive: it doesn't need to be generated or shaped in a particular way - it can have any object added to it, becoming "tracked." There can be two kinds of wrappers: your own custom wrapper class that typically inherits from some other POCO and adds "framework-friendly functionality," and "infrastructure wrappers" that are more like DataTable's, except they derive from DynamicObject. The framework can use multiple flavors of these objects:
The key is flexibility: you can mix-and-match approaches even within a single app! In fact, our demo app does this by using a Person POCO, along with a PersonWrapped wrapper (theoretically code generated). The Phone POCO does not have a corresponding PhoneWrapper, but that's okay - we don't need it since the infrastructure wrapper used will be provisioned with more services than it would be if you had a wrapper (or POCO) that say implemented INotifyPropertyChanged. In release 0.2, the main way to interact with the database is using stored procedures. As mentioned in the design goals, this is largely intentional, but it is just one way to implement data access, which is done using a provider model. Use of stored procedures as the "data layer" is by convention: you would typically name your procedures up_[ClassName]_i (for insert), up_[ClassName]_u (for update), up_[ClassName]_d (for delete), up_[ClassName]_ByKey (retrieve by primary key). (The naming structure can be overridden based on your preferences.) Beyond CRUD, you can craft your own retrieval procedures that may map to existing class layouts - or identify completely new formats. The sample app and test cases are good places to start in understanding what's possible! In fact, the sample WPF app demonstrates some functionality you won't find in the automated tests. For example, UI data binding is illustrated here:
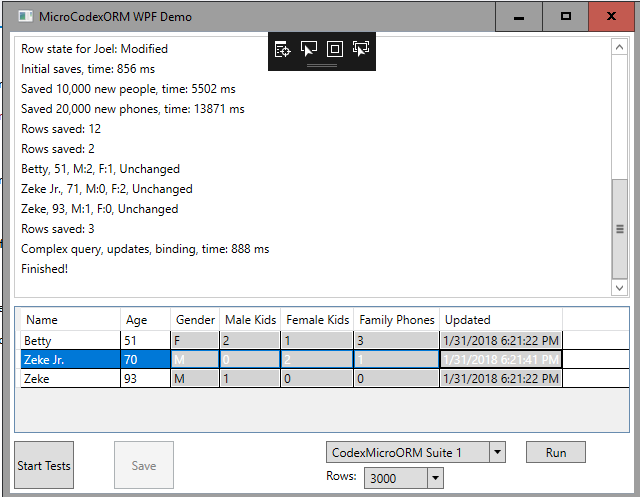
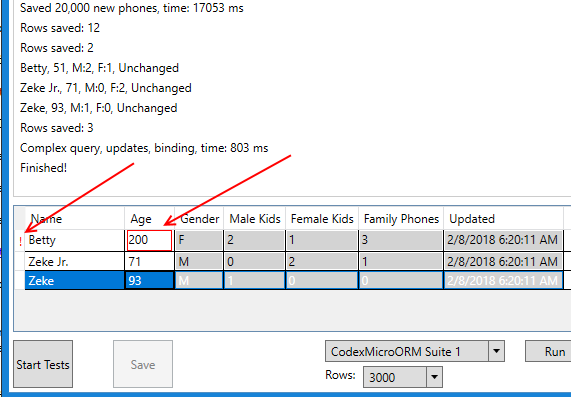
Once you've clicked on "Start Tests" and some data has been created in the database, you're able to maintain these "people" records showing in the grid: try updating a name or age and click Save. You should see the Last Updated Date column change values, and the save button itself should be enabled/disabled based on the "dirty state" (and registered validations) of the form - something that CEF makes easy using this type of pattern: It's important to acknowledge what's going on here: your existing POCO may not implement INotifyPropertyChanged or IDataErrorInfo, but CEF offers it silently in a way that makes data binding easy - something not overly easy in many other frameworks. Furthermore, as of 0.2.4 we've included data validation which WPF is aware of through IDataErrorInfo. For example, the demo app has added a static validation for a person's Age: Now if we enter an invalid age, the grid can easily be made to present the situation as an error:
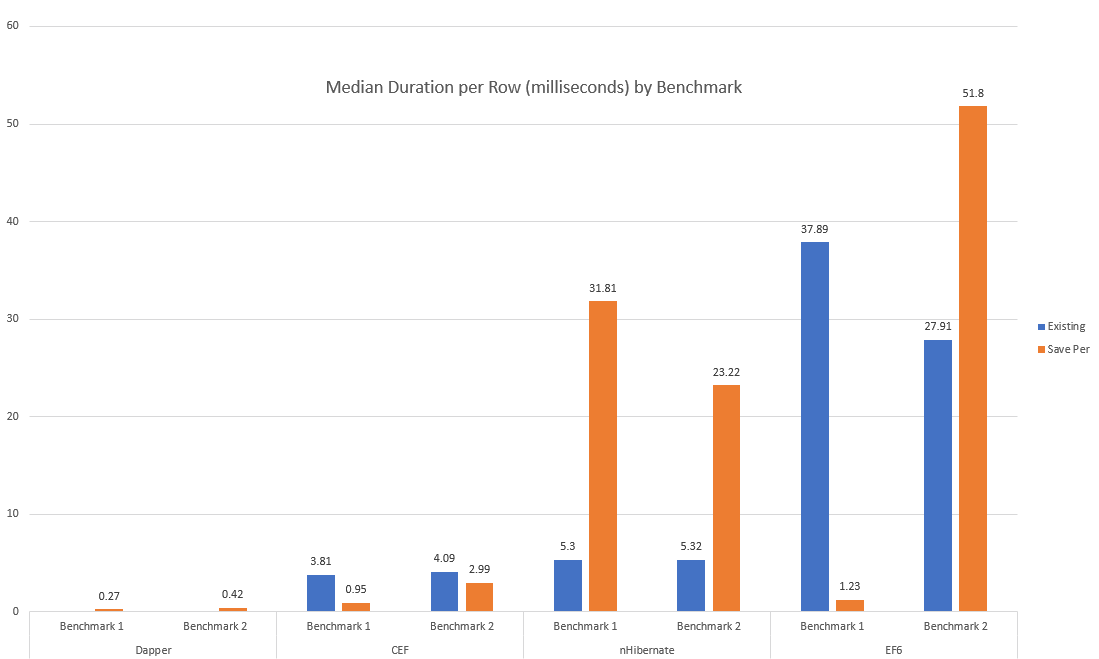
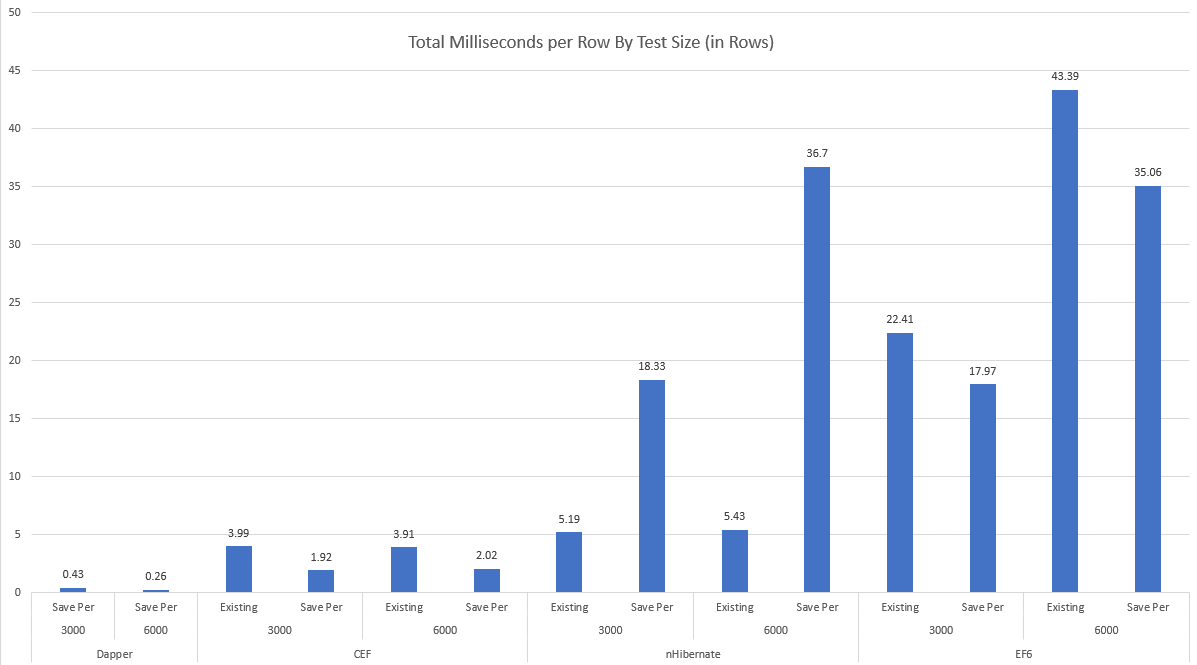
Also - keep an eye out for CodexMicroORM.OODB. This will be a NoSQL offering (in reality, more HybirdSQL) that plays nicely with CEF, offering an ultra-optimized in-memory object-oriented database with variable levels of ACID support. The idea here would be to eliminate the need for ORM altogether - there's no "relational" model to map your object model to! We'd be cutting down on architectural layers (including the entire TCP/IP stack for talking to your database - this is envisioned as an in-process database where you simply add a NETStandard2 NuGet package and voila: you've got persistence for your objects virtually anywhere!). (If you're watching our caching module, you're seeing some clues on our direction.) Sample / Testing AppI've included both a sample app (WPF) and a test project. The sample app illustrates UI data binding with framework support, along with a series of scenarios that both exercise and illustrate. We can see for example with this class: "Kids" is an object model concept where in the database this is implemented through a ParentPersonID self-reference on the Person table. We should be able to do this: ... and expect that Zella's ParentPersonID will be nullified when it's saved by the call to DBSave(). Most of this magic happens because we've established key relationships early in the app life-cycle: This code is something that we can ideally eventually generate, as opposed to writing it by hand. Update (as of approximately 8/1/18): XS Tool Suite will be generally available and includes templates that support generation of C# code from existing databases, including the ability to decorate generated code with keys, relationships, defaults, and more - along with strongly-typed stored procedure wrappers and enumerations. All of that can be "applied" with one line of code: AttributeInitializer.Apply(). I'll be providing more details on this in an up-coming blog post. (The current release (0.7.3) of CEF is needed to take advantage of these new templates.) In terms of the SQL to support these examples: a .sql script is included in both the test and demo projects. This script will create a new database called CodexMicroORMTest that includes all the necessary schema objects to support the examples. You may need to adjust the DB_SERVER constant to match your own SQL Server instance name. The SQL that's included is a combination of hand-written stored procedures and code generated objects, including procedures (CRUD) and triggers. The code generator I've used is XS Tool Suite, but you can use whatever tool you like. The generated SQL is based on declarative settings that identify: a) what type of optimistic concurrency you need (if any), b) what kind of audit history you need (if any). Of note, the audit history template used here has an advantage over temporal tables found in SQL 2016: you can identify who deleted records, which (unfortunately) can be quite useful! CodexMicroORM plays well with the data layer, providing support for LastUpdatedBy, LastUpdatedDate, and IsDeleted (logical delete) fields in the database. Update: I've published a blog article that gets into detail on this topic of SQL data auditing. Update: deeper tool support has arrived with XS Tool Suite 2018 Volume 1. This version includes templates that can generate your business object layer (with settings via attributes), do your SQL data audit + CRUD procedures, and more! Performance BenchmarksIn release 0.2.1, I've enhanced the WPF demo to include a benchmark suite that tests CodexMicroORM, Entity Framework, nHibernate and Dapper. I selected these other frameworks on the expectation that they've "worked out the kinks" and we should be able to judge both performance and maintainability (code size). The methodology for testing is to construct two types of test (benchmarks 1 and 2) that can be replicated in all four frameworks. Benchmark 1 involves creating new records over multiple parent-child relationships. Benchmark 2 involves loading a set of people based on some criteria, updating them and saving them (and in some cases, their Phone data). I assume the goal output for all frameworks is to populate and save object models that might end up being passed to different components for further processing. This implies we should have all system-assigned values present in memory by the time each test finishes. I also tried to implement the fastest solution possible by introducing parallelism where a) it improved performance, b) the framework allowed it without returning errors. I also chose solutions that resulted in the least possible "tweaking" - mostly out-of-the-box settings or patterns that might seem obvious to a relative framework newbie. I feel this is fair since if you're an expert in any of these frameworks, chances are you won't be comparing them: you'll be using the one you know best and are likely to self-adjust your coding style based on what you know works best. (Whether that's good or not for say maintainability - that's open for debate.) For measuring code size and performance, I omit code that can be considered "initialization," "start-up only," and "code generated or ideally code generated." This includes virtually all of the SQL objects in our sample database, except for a couple of hand-written procedures (e.g. up_Person_SummaryForParents). I've excluded the size of up_Person_SummaryForParents from the code stats mainly because it can be considered general-purpose and usable by all frameworks, if needed. (For the record, it's 838 characters.) Here are execution times, per row, for the various frameworks:
These numbers combine two tests: one with 3000 rows and one with 6000 rows. "Existing" is the case where we take an existing, pre-populated object model and try to save it, in its entirety, based on the ORM's ability to understand whether rows are added, modified or deleted. "Save Per" is a modified version where we end with the same set of rows in the database, but we're committing changes "per parent entity." I had originally intended to just test "existing" but it became evident that there's a substantial difference in the styles between frameworks. (You can use this to inform how to use these frameworks and get some understanding of their inner workings.) Here are execution times, split based on whether we try to save 3000 or 6000 initial parent entity rows:
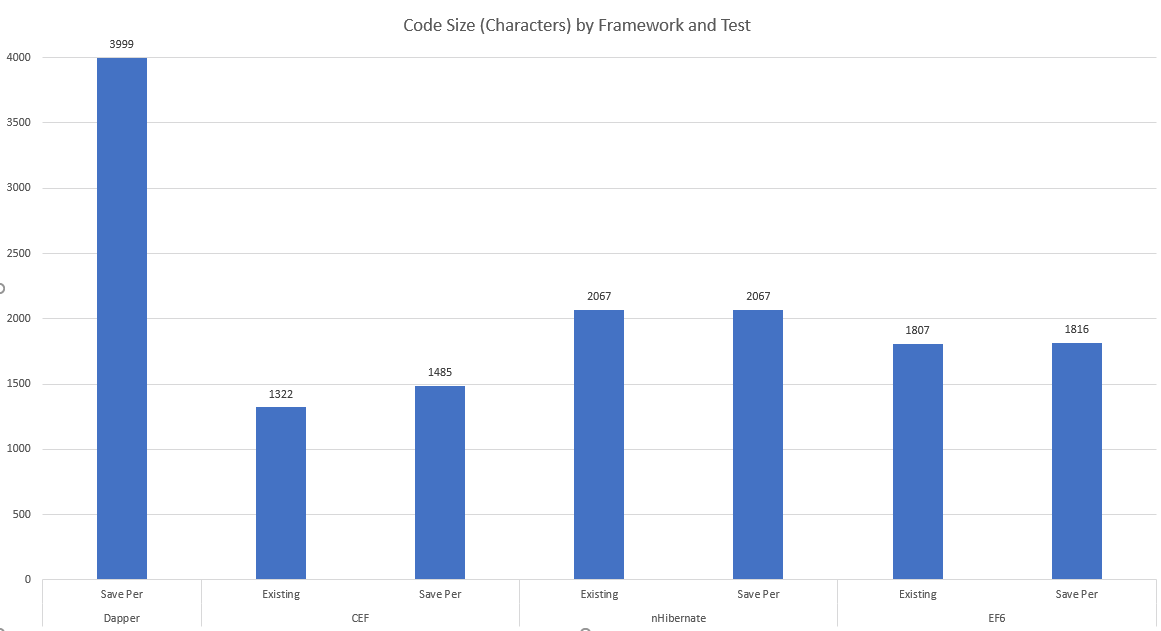
Frameworks that don't keep their performance characteristic steady when increasing the data set size are non-linear - performance is worse than O(n). Another metric is how much code we need to write to implement the scenario, shown here:
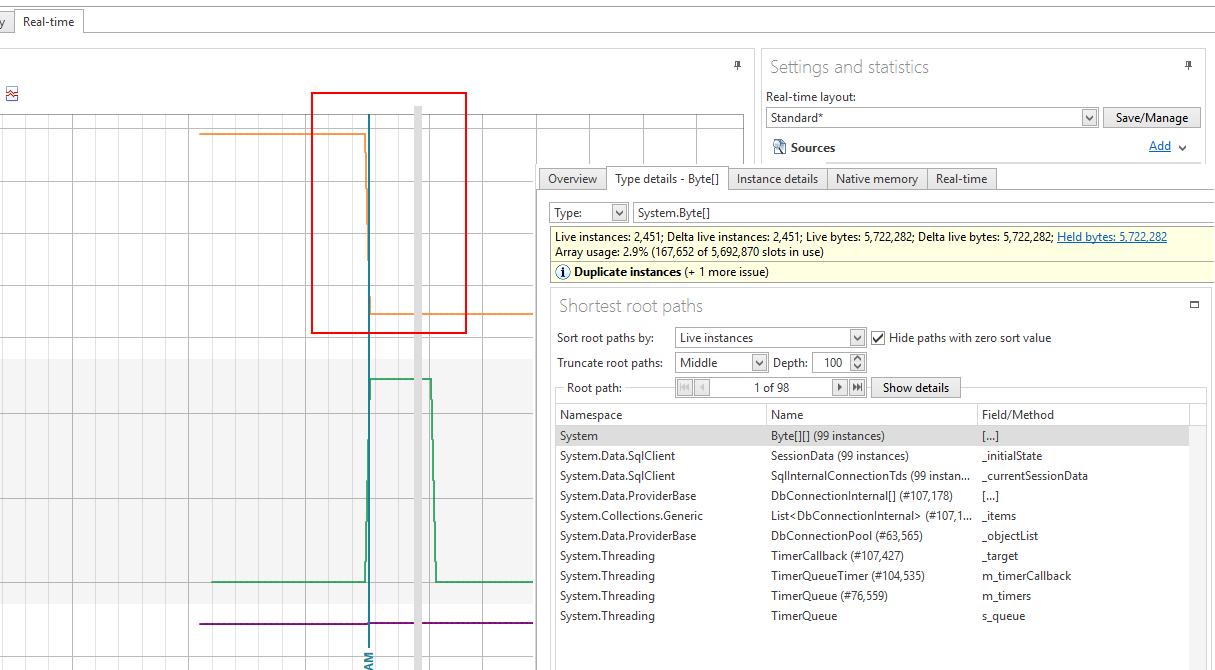
The higher the character count, the more code that was needed - a logical assumption is the complexity is higher and the maintainability is lower. Raw performance data is available here. Entity Framework ResultsThe biggest concern I have with the EF results is that they're non-linear. Compare performance per row between the 3000 and 6000 row cases: the 6000 row case has nearly doubled the per row time, regardless of approach! This is not a good story for scalability. The EF appologist might say: "you shouldn't be using it in the way you're testing it here - it's not intended for that, use a different choice like Dapper if you need extreme performance or are dealing with many rows." I'd respond by saying the purpose of the comparison is to see if there does exist a general-purpose ORM framework that has linear performance in what amounts to randomly selected scenarios. Dapper succeeds (but as I discuss below, it has its own down-sides), and so does CodexMicroORM - but both EF and nHibernate fail the test in at least one scenario. I'm willing to be told "but you could have done things differently with framework X and it would have given much better results" - but again, the most obvious approach should be measured since if we require "deep knowledge" of the framework, chances are good we'll be cutting "bad code" for a while, until we've learned its ins-and-outs. If we could achieve good results with intuition, that would be ideal, of course. Generally speaking, EF is not thread-safe and trying to introduce Parallel operations resulted in various errors such as "The underlying provider failed on Open" and "Object reference not set to an instance of an object", deep within the framework. There was also an example of needing some "black box knowledge" where I had to apply a .ToList() on an enumerator, otherwise it would result in an obscure error. I'm not a fan of this "it doesn't just work," although we could argue it's a minor inconvenience and most frameworks have some level of "black magic" required. We might give extra marks to EF6 in its ability to properly interpret our LINQ expression in Benchmark 2 and thereby avoid use of the general-purpose stored procedure, up_Person_SummaryForParents. However, we might not always be so lucky: using procedures will make sense in situations where we need to use temp tables or use other SQL coding constructs to squeeze out good performance. It might surprise you that I'm not opposed to using EF to get nice advantages such as lazy loading. CEF is light-weight and can interop with really any other framework since it's simply about wrappers and services for existing objects. So imagine being able to helicopter-drop it in (as easy as adding a NuGet package!) to solve problems where other frameworks start to feel pain: that's supported today. nHibernate ResultsLet's face it: nHibernate must deal in stylized objects, not necessarily true POCO that might pre-exist in your apps. The clearest evidence is the fact all properties must be virtual - you may or may not have implemented your existing POCO's with that trait. The counter-argument could be "but you're requiring CEF objects expose collections using interfaces such as ICollection instead of concrete types." My counter-counter argument would be, "there's no strict requirement here - but you do lose some framework 'goodness' and may need to do more 'work' to get your desired results," and "it's a common and generally good design pattern to expose things like collections using interfaces so you can hide the implementation details." Something you might notice in the code is the nHibernate solution includes quite a bit of set-up code. I chose to use the Fluent nHibernate API, but the XML approach would have resulted in quite a bit of configuration as well. I also spent a bit of time trying to understand the ins-and-outs of the correct way to do the self-referencing relationship on Person, and borrowed the generated EF classes which match the database structure completely. On the performance side, nHibernate scales linearly with the "save existing object model" scenario - but it does not for the "save per parent entity" case. (This would also match a case where we chose to use database transactions to commit per parent entity.) Like EF, parallelism was not kind to nHibernate and I had to avoid it generally. Another minor consideration is the fact as of today (12/31/17), nHibernate does not support NetStandard 2.0. Dapper ResultsIt became evident as I tried to implement the Dapper solution that it's not really the same style or purpose as the other ORM tools. I'd call it more of a "data access helper library" instead. Unlike the other frameworks tested, it does not track row state: it's up to you as the developer to know when to apply insert, update or delete operations against the database. This helps it achieve its excellent performance, but it's just a thin wrapper for raw ADO.Net calls. Because of this, I didn't attempt a "populate and save all" version of tests for Dapper: it only really made sense to do the "save per parent entity" method. If we constructed a way to do a generalized "save" using Dapper, chances are good we'd lose the extreme performance benefits since we'd be applying the principles that make other frameworks slower. Dapper although the clear winner on performance was the clear loser on code size / maintainability. Anecdotally, I also had more run-time errors to debug than other framework examples since there's no strong typing. Similarly, changes in the database schema are more likely to cause run-time errors for the same reason: no strong typing we could tie back to code generation. (Although I'm sure if I looked hard enough, someone has created templates to act as wrappers for database objects.) This in turn speaks to its nature, much as EF and nHibernate, being more highly-coupled with your database than you might want to believe (e.g. requiring ID's to support relationships, etc.). CodexMicroORM ResultsCEF offers linear performance results and has among the smallest, most succinct code implementations. It's worth noting that you can use EF-generated classes, if you like, with CEF. I did an extra test for CEF that I did not include for other frameworks - because it's somewhat unique to CEF out-of-the-box - the ability to save added data using BULK INSERT. That case for Benchmark 1 yielded a median time of 0.9 ms/row (both 3000 and 6000 row runs). This is the fastest way to "save an existing, full object graph" among all tests. The trade-off? You don't get PhoneID's assigned in memory at the end of saving. Am I claiming that CEF is "perfect"? Certainly not: this is version 0.2.1 - but I'm quite confident it's positioned well to offer O(n) performance based on data set size. If you discover something slow, let me know! Finally, I wanted to verify that CEF has no memory leaks as part of the demo program. I did this using a memory monitoring tool, issuing a snapshot / garbage collect after all CEF tests were complete:
The orange line is allocated memory - within the context of the red box, this is where a collect had been issued and the orange line has dropped to near-zero. The Type Details shows us what's the largest "left over" allocated objects: mainly ADO.Net static data that we have no control over. Conclusions
Update (0.2.3): CEF Beats Dapper Performance With Async SavingAs of version 0.2.3, I've introduced a new feature that makes a big enough difference for performance that in a new benchmark, CEF beats Dapper performance by 45%! This feature is asynchronous saving and can be enabled globally: ... or at a service scope level: ... or on an individual request level: I've added a new benchmark test in the WPF demo app, implemented for both Dapper and CEF:
(I stuck with just these two frameworks since it's clear from the prior testing that nHibernate and Entity Framework aren't remotely competitive in terms of performance.) The nature of this new benchmark is to work with a pre-populated set of database records, retrieving data in a loop and making a couple of updates in the process. We've also split some of the functionality into multiple methods where the parameters are restricted to ID values, like we might see in a theoretical library / API. The final results for both CEF and Dapper are verified in the database at the end. Of note:
Doing the Execute() with in-line use of parent.ParentPersonID and parent.Gender results in run-time errors, and the simplest, most desirable approach of simply using "parent" as the second parameter does not work, either. The final performance result is that Dapper's per-database-call timing averages 0.47 milliseconds, whereas CEF is 0.34 milliseconds - nearly 30% faster than Dapper. In terms of code size, CEF's implementation is 1618 characters compared to Dapper's 2629 characters - meaning CEF in this example offers a 30% performance gain with nearly 40% less code to write and maintain! Now, there are ways to achieve similar results using Dapper - by writing even more code. CEF's implementation of async saving leverages a combination of in-memory caching and parallel operations that we can synchronize on as needed. (In fact, leaving your current connection or service scope ensures all outstanding async operations will be complete.) The use of the new MemoryFileSystemBacked caching service is something I'll cover in a future blog post, but in this particular benchmark, async saving was the clear way to "win" against Dapper. It's also worth noting that with 0.2.3, some of the performance figures were lowered due to performance tweaks - but in 0.2.4, we gave back some performance with the addition of important new features. These types of changes will happen natually and I'm not going to redo performance comparisons after every release. (I didn't do a perfect job when evaluating the other frameworks, too, giving them a pass in some respects - e.g. did not round-trip all values, which would have increased the code size in cases). Some may say, "benchmarks can be made to prove anything you want" - which is true, but quantitative analysis offers at least something objective, where measuring things like "features and style" is much more personal. Suffice it to say that offering great performance and advanced services is a goal and look for more goodies in up-coming releases! Where Do I Start?I suggest doing a clone to grab the full code base. The test project has a number of important use cases, illustrating capability. The WPF demo project includes performance benchmarking, but also shows general concepts, contrasts patterns with other frameworks, and illustrates live WPF data binding. You can include CEF in your own projects using NuGet: NuGet - Core, Nuget - Bindings. I'll be providing further updates both here and on my site. Registering on xskrape.com has the added benefit of getting you email notifications when I release new blog articles that provide deep dives into the concepts you see here. DocumentationOn-line documentation will become available, with your feedback and encouragement. In the meantime, many of the concepts will be covered through blog articles. Also, click "Watch" above to keep track of updates made here on GitHub. Want to see even more? Share, watch, clone, blog, post links to this project - and mention it to your friends! Contribution and development is proportional to community interest! This framework will be a drop-in replacement for my "old" framework in many projects (templates to come), so will receive increasing production attention. Release Notes
Roadmap / PlansLook for in coming releases:
Come and subscribe to blog updates. Have opinions about what you'd like to see? Drop me a line @ joelc@codexframework.com. Pull requests are welcome, too. |