General Description
Azure Pipelines task facilitates an integration between Azure DevOps Pipeline (Build / Release) and Azure Data Explorer (ADX) databases.
This extension includes 3 basic tasks:
- Azure Data Explorer Command - Run Admin Commands against ADX cluster
- Azure Data Explorer Query - Run Queries against ADX cluster and parse the results
- Azure Data Explorer Query Server Gate - Agentless task to Gate releases depending on the query outcome
The content and functionality of the tasks can be taken from either a git source control or build sources or build artifacts or inline the task.
The tasks authenticates with AAD App details (ID / Key) either from variabes or an Azure DevOps Service endpoint.
Additionally, ADX Query Task and ADX Command task authentication can also be done using Workload Identity Federation (WIF) and Managed Identity via AzureResourceManager service connections. Read more about Azure Resource Manager(ARM) Service Connections.
Note: Kusto fabric cluster url is not supported for WIF and MI auth.
Official Azure Data Explorer - Azure DevOps integration
Authentication Methods
Below are the authentication methods supported by the Azure Data explorer tasks:
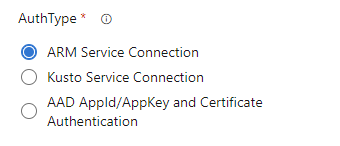
Select the appropriate authentication type (ARM service connection/Kusto Service connection/AAD Auth/certificate based auth) and provide the necessary details.
Azure Resource Manager(ARM) Service Connection
Microsoft Entra application (AAD) Authentication/Certificate based Authentication
Add your AppID, AppKey and TenantID (Use Variable Group or Secret Build Variable)
the Resource URI is the service endpoint providing the jwt token requested for accesing your cluster
should be the base URL for your cluster,
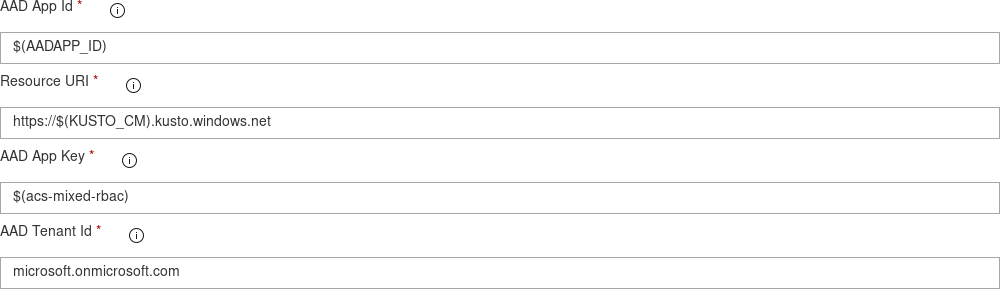
Azure Data Explorer Service Endpoint
UPDATE: With versions 4.0.x and up ADX Service Endpoint now supports Workload Identity Federation(WIF) Authentication. Learn setting WIF authentication with ADX service Endpoint for Agent (Publish, Query) and Agentless (Deployment gates) tasks.
You can Use an Azure Data Explorer Service Endpoint
Check the "Use Service Endpoint" Checkbox to select an existing Azure Data Explorer service connection

if you don't already have a Service connection configured, click the "Manage" link to create a new service connection
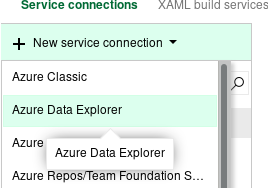
Setting up WIF authentication in Kusto Service Endpoint
Go to Project Settings -> Service connections -> New service connection -> Azure Data Explorer
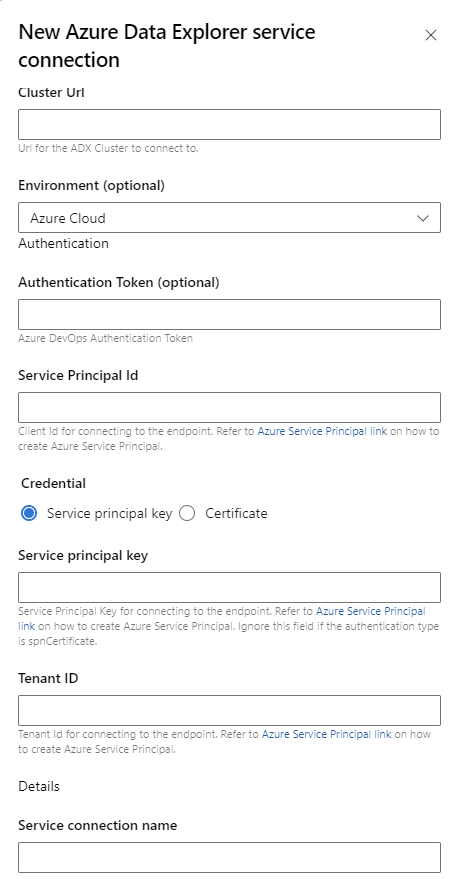
Create ADX Service Endpoint with WIF authentication, Enter your Cluster URL, Service Principal Id, TenantID in the Service connection appropriate Fields. Set "Service connection name" and save.
Go to Azure portal to load your Microsoft Entra App of your service principal, which you put the service principal id in service connection of steps above.
Open "Certificates & secrets" section and switch to "Federated credentials" tab.
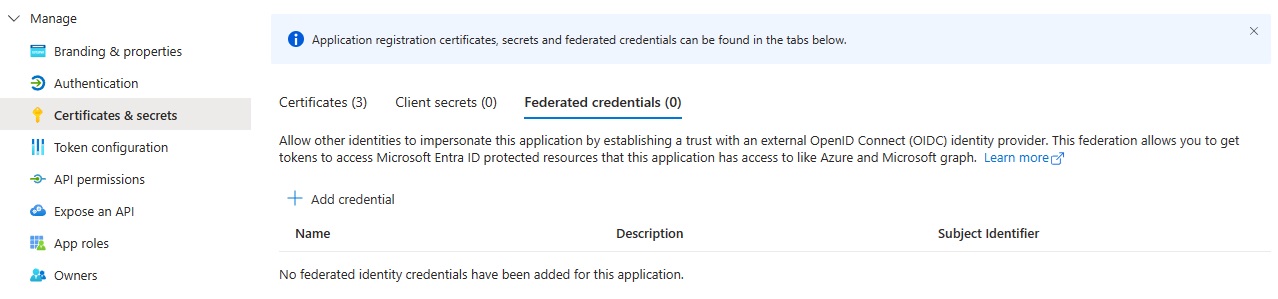
Click "+ Add credential" button
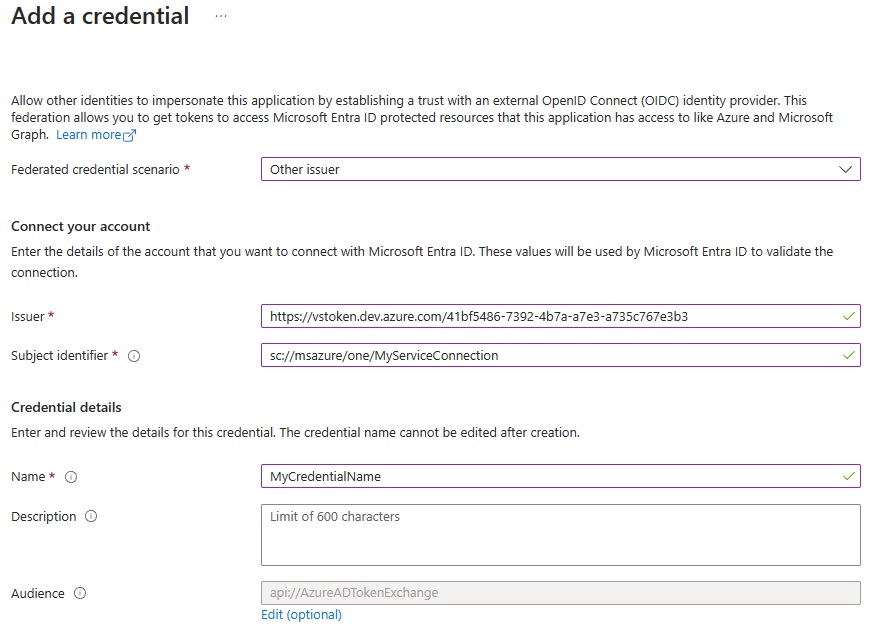
Select "Other issuer" for "Federated credential scenario".
Enter issuer and subject identifier, by copying the details from the ADX service connection's overview page.
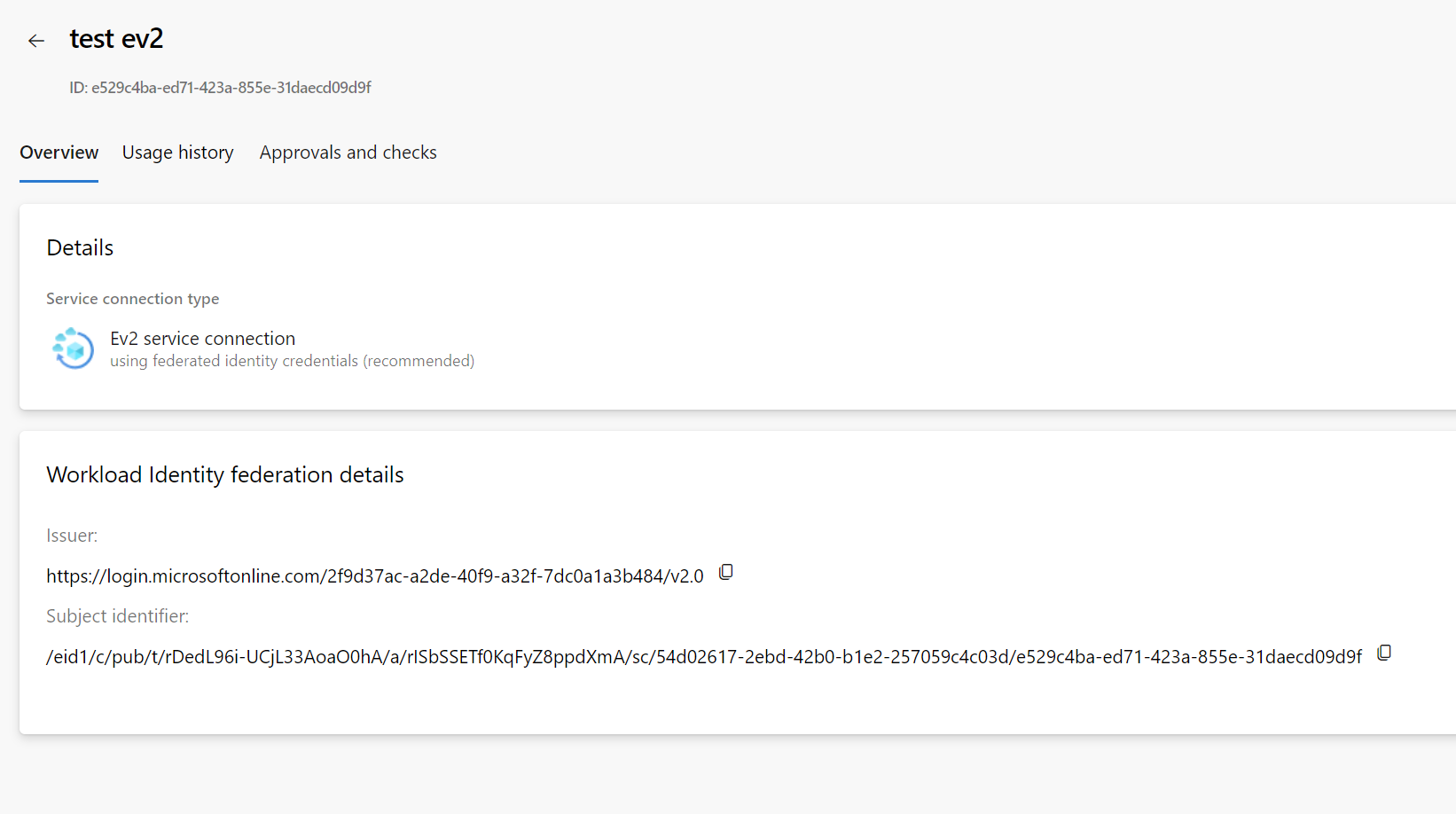
Give a "Name" in "Credential details" and click "Add" button.
Details
Azure Resource Manager Service Connection
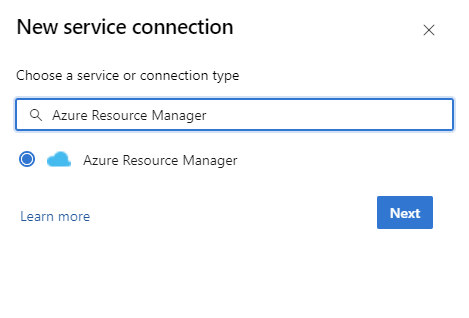
Choose new service connection under project settings, and select Azure Resource Manager.
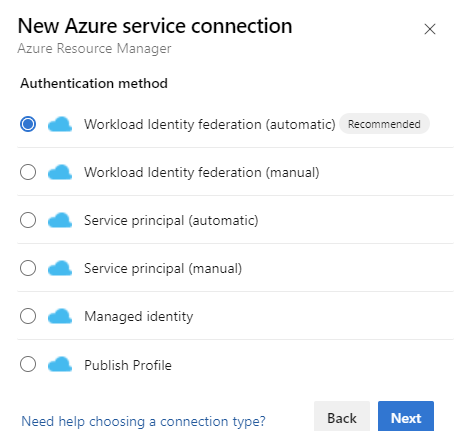
Select Work load Identity Federation (WIF)(Automatic/Manual) OR Managed Identity as the authentication method.
Note: Currently Kusto Task supports only WIF (automatic/manual) or Managed Identity for ARM service connections.
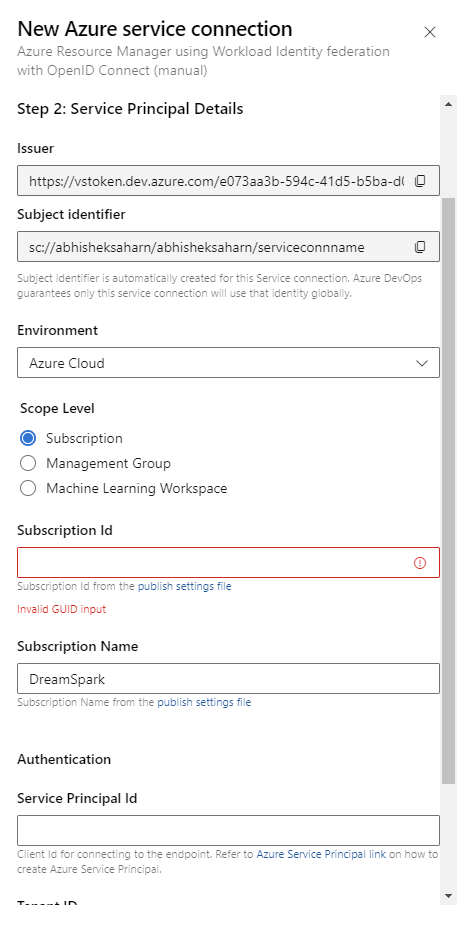
Automatic Workload Identity Fedreation(WIF) will publish details automatically in contrast to Maual WIF where you need to provide the details manually.
Read more about Azure Resource Manager(ARM) Service Connections.
Azure Data Explorer Endpoint
To create a new service connection go to project settings page (the gear icon in the lower lefthand side)
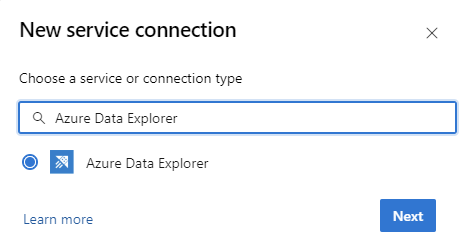
if you have service endpoints created before version 1.7.1 you might need to recreate them for the server gate task to work properly
Select the authentication type, Service Principal Authentication (AppID/AppKey) or Workload Identity Federation (WIF)
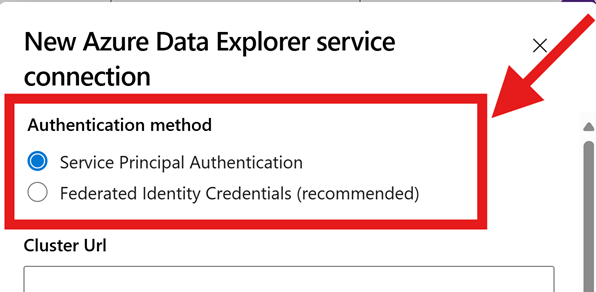
Service Principal Authentication:
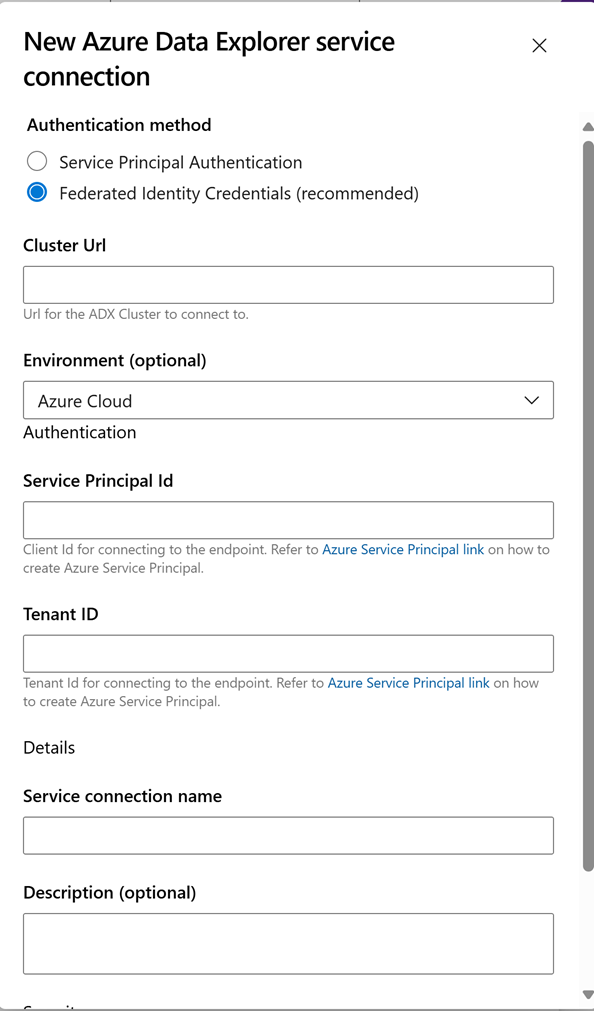
Workload Identity Federation (WIF):
- Enter your Cluster URL, Service Principal Id, TenantID in the Service connection appropriate Fields. Set Service connection name and save.
Read about setting up WIF credentials in Microsoft Entra App here
Admin command task
Add your endpoint information (Cluster and Database) to Endpoint URLs (optional: use values from build variables)

Select the appropriate authentication type (ARM service connection/Kusto Service connection/AAD Auth/certificate based auth) and provide the necessary details. Check section Authentication Methods for more details.
Add the match pattern for your *.csl files from the Source Control (for running multiple commands in the same task)

the single line option allows having multiple files, with one command per file
Alternatively: switch to an inline script and write your command directly in the task (no empty lines - one command per task)

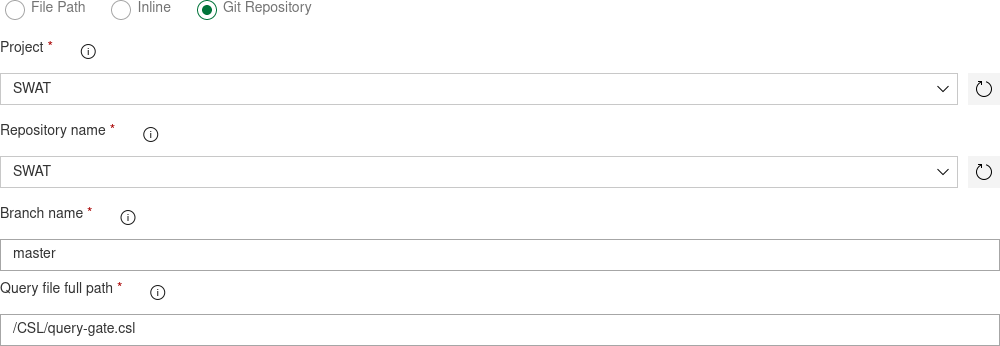
OR: Add you file directly from a git repository path
In case the command is a long running asynchronous operations you can check "Wait for long Async Admin commands to complete"

checkbox to have the task run .show operations <Guid> in the REST response, and the task will wait for the command to complete pass or fail based on the result (Task will fail if any command in the script is not async - Use only on async commands)
Optional: Add the name of the output variable (Or Path to output file) you want to command response to be stored in (and use it in downstream tasks)
if you run multiple commands only last query is saved, when "Save only last response is unchecked multiple variables will be created (one foreach command and endpoint - with ' prefix' for filenames or ' suffix' for variables)"

Yaml Sample Usage
steps:
- task: Azure-Kusto.ADXAdminCommands.PublishToADX.ADXAdminCommand@5
displayName: '<Task Name>'
inputs:
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
#authType: 'armserviceconn or kustoserviceconn or aadcert'
authType: '<auth type name>'
connectedServiceName: '<Service Endpoint Name>'
serialDelay: 1000
continueOnError: true
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Query task
Add your endpoint information (Cluster and Database) to Endpoint URLs (optional: use values from build variables)
Select the appropriate authentication type (ARM service connection/Kusto Service connection/AAD Auth/certificate based auth) and provide the necessary details. Check section Authentication Methods for more details.
Add the match pattern for your *.csl files from the Source Control (for running multiple commands in the same task)
the single line option allows having multiple files, with one command per file
Alternatively: switch to an inline script and write your command directly in the task (no empty lines - one command per task)

OR: Add your file directly from a git repository path
Query Exit Criteria: you can choose to fail the task based on the response record (rows) count

or based on the response (single) value (make sure the query only returns a single record (row and field))

Optional: Add the name of the output variable (Or Path to output file) you want to command response to be stored in (and use it in downstream tasks)
if you run multiple commands only last query is saved, when "Save only last response is unchecked multiple variables will be created (one foreach command and endpoint - with ' prefix' for filenames or ' suffix' for variables)"
Server Gate
Release gates documentation
Once we go to Release Definition, by accessing pre/post approval setting we can enable Gates and add Azure Data Explorer Query as a Gate
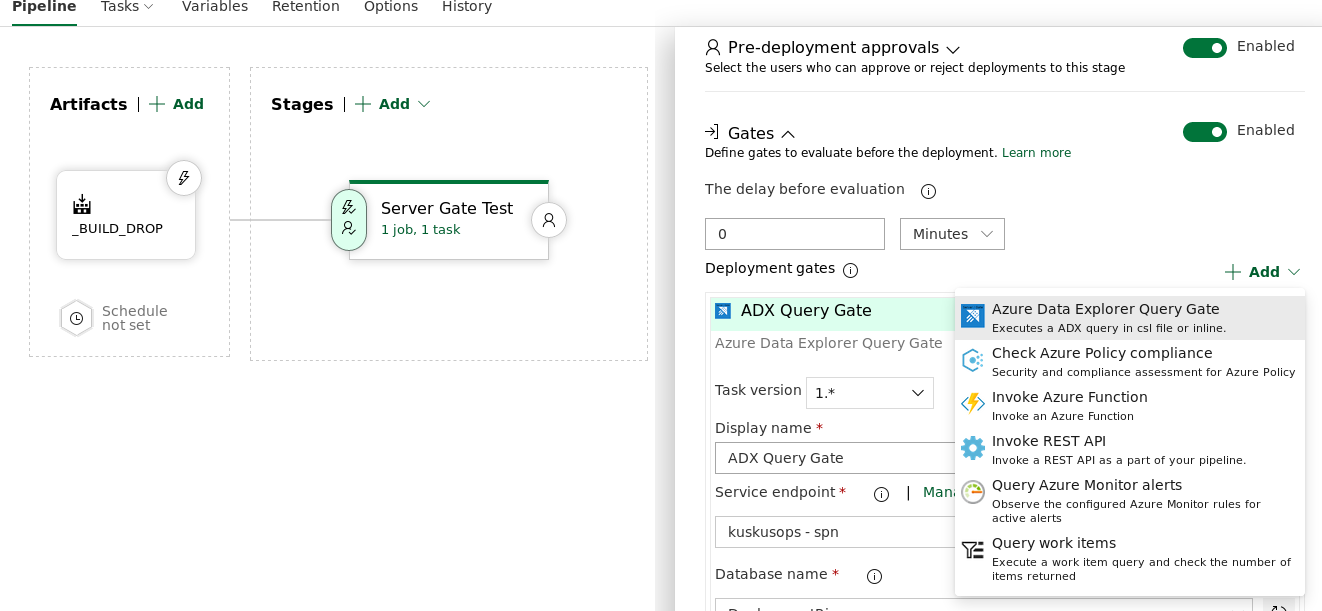
We can query ADX using Inline query
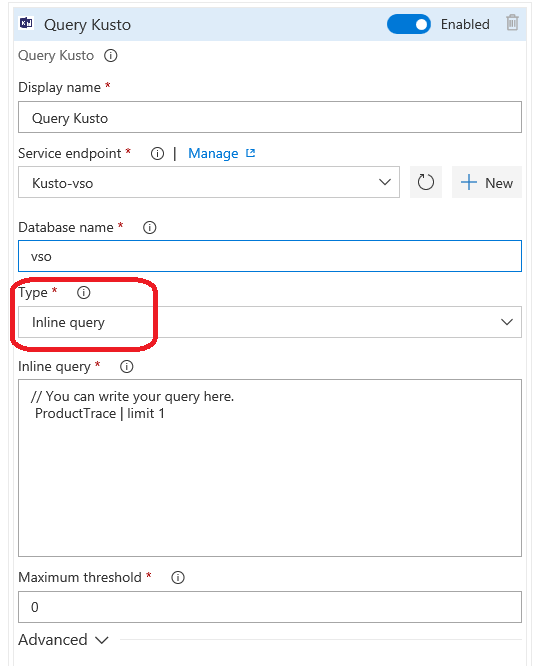
We can query ADX using File path
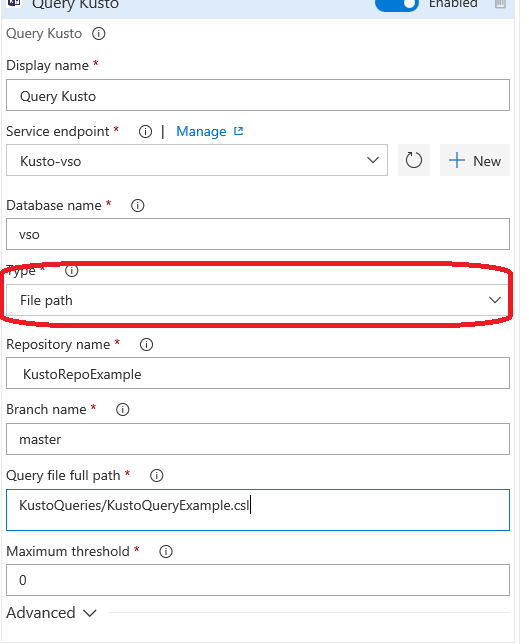
How to add an endpoint to be used by Azure Data Explorer Query Gate or Task
Getting ApplicationId and ApplicationKey
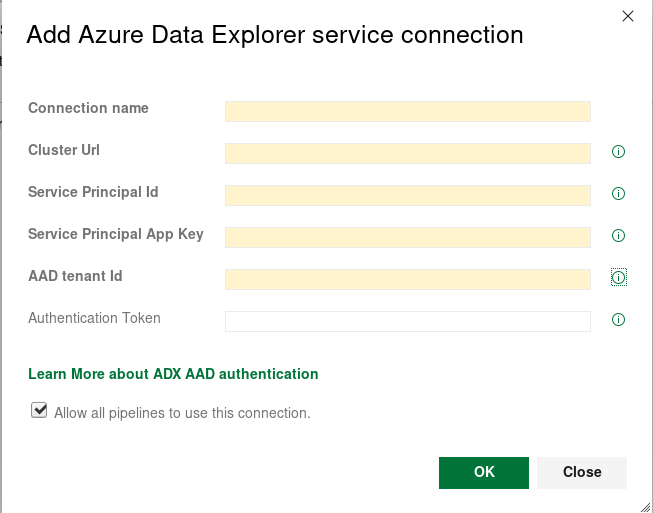
How to add Query Kusto as a Task

Service endpoint: Select an ADX endpoint that should be used to connect to Kusto, to execute the query. Check section How to add an endpoint to be used by ADX Query Gate or Task to add an ADX endpoint.
Database name: ADX database name to run the query. example: vso or vsodev.
Type: Query can be taken from a repository file path or inline.
Parameters for Inline query
Inline query: You can write your Kusto query. More info on Kusto query language.
Parameters for File path
Repository name: Repository name in which query file exists.
Branch name: Branch name in which query file exists. example, master.
Query file full path: Query (csl) file full path in the given branch. example, /MyKustoQueries/KustoQuery.csl.
Maximum threshold: The maximum number of rows from the query result.
Minimum threshold: The minimum number of rows from the query result.
How to adjust threshold
Max and min threshold are output rows expected from the Kusto query
Yaml Sample Usage
Note: The authType input is recommended to specify explicitly. If omitted, it defaults to armserviceconn, which requires a connectedServiceARM input.
Using ARM Service Connection (default)
steps:
- task: Azure-Kusto.ADXAdminCommands.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
script: |
.show version
kustoUrls: 'https://<ClusterName>.kusto.windows.net:443?DatabaseName=<DatabaseName>'
authType: armserviceconn
connectedServiceARM: '<ARM Service Connection Name>'
minThreshold: 1
maxThreshold: 1
Using ADX (Kusto) Service Connection
steps:
- task: Azure-Kusto.ADXAdminCommands.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net:443?DatabaseName=<DatabaseName>'
authType: kustoserviceconn
connectedServiceName: '<Service Endpoint Name>'
continueOnError: true
Using AAD Certificate Authentication
steps:
- task: Azure-Kusto.ADXAdminCommands.ADXQuery.ADXQuery@5
displayName: '<Task Display Name>'
inputs:
script: |
.show version
kustoUrls: 'https://<ClusterName>.kusto.windows.net:443?DatabaseName=<DatabaseName>'
authType: aadcert
aadClientId: '<AAD App ID>'
aadClientCert: '<PEM Certificate Content>'
tenantId: '<Tenant ID>'
minThreshold: 1
maxThreshold: 1
Run the task in a CI pipeline and see the JSON results in the log,
or, alternatively, get it in downstream tasks with the Output Variable $(OutputVariable)
You can save it to file or parse it with JSON parsing tool
Contributions
This extension is maintained by Kusto Ops Team Publisher Page
Microsoft docs
Official Microsoft Documentation Site for Azure Data Explorer
Github
Developer Private Fork
Official Azure Pipeline tasks